Client Background and Business Context
The client was a beverage alcohol analytics and advisory firm supporting: Bourbon and tequila brands Regional distributors Multi-state liquor retailers Investment and market research teams Their objective was clear: Build a single, clean dataset that allows apples-to-apples comparison of liquor prices across retailers and regions. However, their internal analysts faced constant friction due to inconsistent product naming, pack-size representation, and attribute formatting.
The Core Problem: Disparate SKU Naming at Scale
At first glance, matching “750ml Bourbon” with “Bourbon 0.75L” sounds trivial. In reality, this problem multiplies rapidly when scaled across thousands of products and stores.
Common SKU Variations Observed Across the three retailers, Food Data Scrape identified variations such as: Bourbon 750ml Bourbon – 750 ML Bourbon 0.75L Bourbon 75cl Bourbon Bottle 750ml Bourbon Whiskey 750ML Despite referring to the same physical product, these SKUs were treated as unique entries in raw datasets.
Why SKU Normalization Matters in Liquor Data
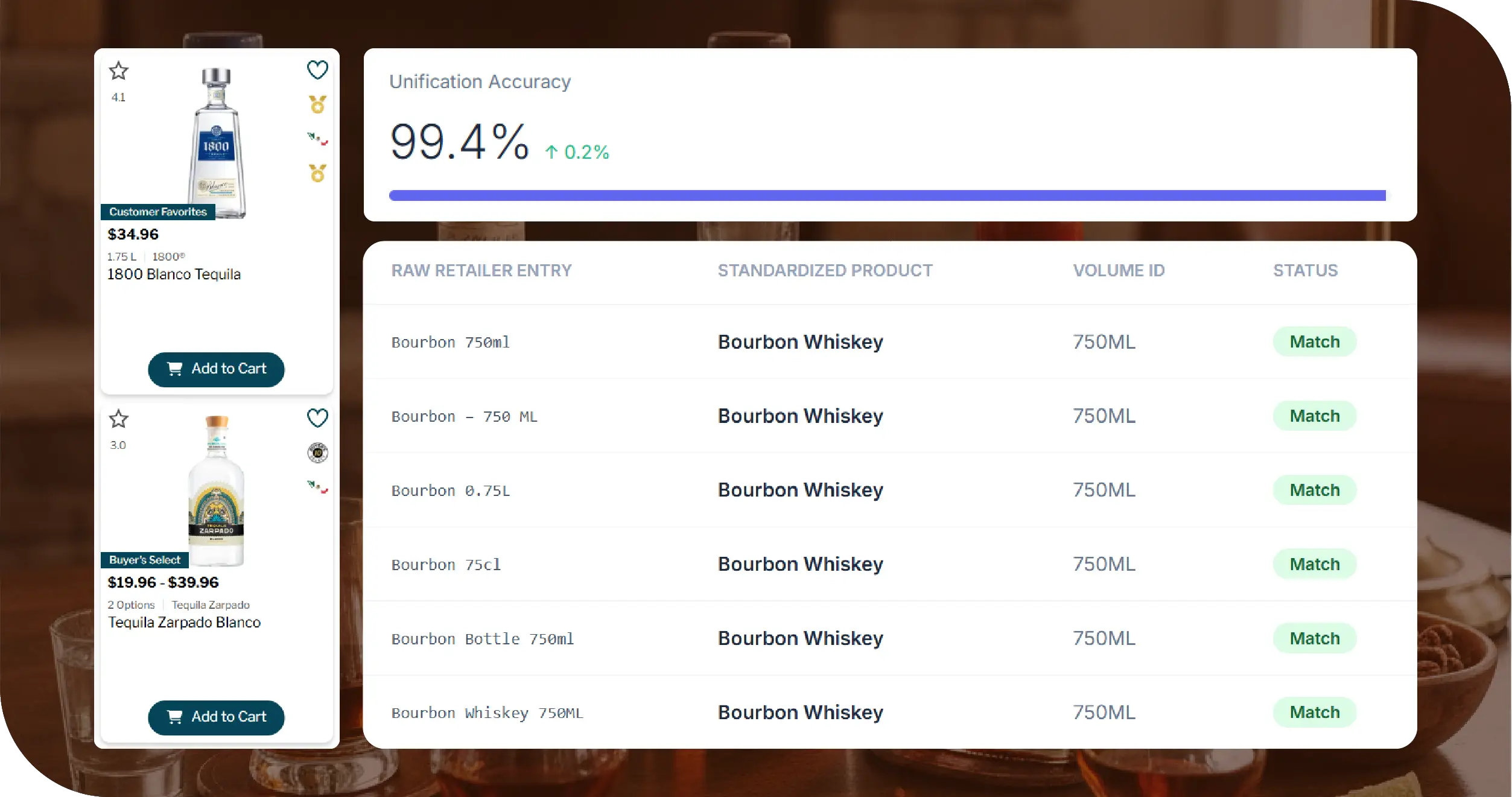
Without normalization, downstream analytics become unreliable.
Business Risks of Unnormalized Data
- Incorrect price comparison
- Duplicate SKUs inflating catalog size
- Misleading regional price gaps
- Faulty promotion and discount analysis
- Broken dashboards and BI reports
For liquor brands and retailers, this can directly impact pricing strategy, distributor negotiations, and revenue forecasting.
Data Sources and Retail Scope
Food Data Scrape worked with structured and semi-structured data extracted from: ABC Fine Wine & Spirits (Florida market focus) Spec’s Wine Spirits & Finer Foods (Texas market focus) Top Ten Liquors (Minnesota market focus) Each retailer followed its own internal catalog logic, making direct SKU matching impossible without transformation.
Step 1: Raw Data Collection and Profiling
The first step was not normalization. It was data profiling. Food Data Scrape ingested raw product listings and analyzed: Product titles Brand fields Size descriptors Alcohol category tags Unit and pack indicators
Sample Raw Data (Before Normalization)
| Retailer | Raw Product Name |
|---|---|
| ABC | Maker’s Mark Bourbon 750ml |
| Spec’s | Makers Mark Bourbon Whiskey 0.75L |
| Top Ten Liquors | Maker’s Mark Bourbon – 750 ML Bottle |
At this stage, none of the rows were technically identical.
Step 2: Attribute Decomposition
Instead of treating SKU names as strings, Food Data Scrape decomposed each product into structured attributes.
Core Attributes Extracted
- Brand name
- Product line
- Alcohol type
- Volume value
- Volume unit
- Packaging type
Example Decomposition
| Raw Name | Brand | Type | Volume | Unit |
|---|---|---|---|---|
| Maker’s Mark Bourbon 750ml | Maker’s Mark | Bourbon | 750 | ml |
| Bourbon Whiskey 0.75L | Maker’s Mark | Bourbon | 0.75 | L |
This step laid the foundation for deterministic matching.
Step 3: Unit Standardization Logic
One of the biggest sources of mismatch was volume representation. Food Data Scrape implemented a standard unit policy: All liquid volumes converted to milliliters Canonical size stored alongside original value
Unit Conversion Rules
- 0.75L → 750ml
- 75cl → 750ml
- 1L → 1000ml
Sample After Unit Normalization
| Brand | Type | Canonical Volume (ml) |
|---|---|---|
| Maker’s Mark | Bourbon | 750 |
| Maker’s Mark | Bourbon | 750 |
This alone eliminated a large percentage of false mismatches.
Step 4: Brand and Keyword Normalization
Retailers often use inconsistent punctuation, casing, or abbreviations. Examples observed: Maker’s Mark vs Makers Mark Don Julio vs DonJulio José Cuervo vs Jose Cuervo Food Data Scrape applied: Controlled brand dictionaries Unicode normalization Stop-word removal Alias mapping tables This ensured brand-level consistency before SKU matching was attempted.
Step 5: Rule-Based SKU Matching
With structured attributes in place, deterministic rules were applied:
Primary Matching Rules
- Same normalized brand
- Same alcohol type
- Same canonical volume
- Same product line keywords
Example Match
| Retailer | Product Name | Match ID |
|---|---|---|
| ABC | Maker’s Mark Bourbon 750ml | MM-BBN-750 |
| Spec’s | Makers Mark Bourbon Whiskey 0.75L | MM-BBN-750 |
| Top Ten Liquors | Maker’s Mark Bourbon – 750 ML | MM-BBN-750 |
This created a single master SKU ID.
Step 6: Fuzzy Matching for Edge Cases
Not all products follow clean patterns. Limited editions, packaging variants, and gift packs required fuzzy logic. Food Data Scrape used: Token similarity scoring Weighted keyword matching Confidence thresholds Fuzzy matching was always: Logged Audited Manually reviewable for critical SKUs This hybrid approach balanced accuracy with scalability.
Step 7: Building the Unified Master Catalog
The final output was a retailer-agnostic master SKU catalog.
Sample Unified SKU Table
| Master SKU ID | Brand | Product | Volume (ml) | Category |
|---|---|---|---|---|
| MM-BBN-750 | Maker’s Mark | Bourbon | 750 | Whiskey |
| DJ-TQL-750 | Don Julio | Blanco Tequila | 750 | Tequila |
Each retailer’s product ID was mapped back to this master SKU.
Downstream Price Intelligence Example
Once SKUs were normalized, true price comparison became possible.
Sample Normalized Price View
| Master SKU | ABC Price | Spec’s Price | Top Ten Price |
|---|---|---|---|
| MM-BBN-750 | 27.99 | 26.49 | 31.99 |
| DJ-TQL-750 | 52.99 | 51.99 | 57.99 |
Without normalization, this table could not exist.
Business Impact Delivered

For Analytics Teams
- Clean dashboards with zero duplication
- Accurate regional price gap analysis
- Faster reporting cycles
For Brands
- MSRP compliance monitoring
- Region-wise pricing discipline
- Distributor performance visibility
For Retailers
- Competitive benchmarking
- Promotion effectiveness analysis
- Margin leakage detection
Why Food Data Scrape’ Approach Works
Unlike generic ETL pipelines, Food Data Scrape builds domain-aware normalization logic.
Key differentiators:
- Liquor-specific attribute modeling
- Retailer-aware naming patterns
- Scalable SKU identity framework
- Auditable matching decisions
This ensures the system works not just once, but continuously as catalogs evolve.
Scalability and Future Expansion
The same normalization framework can be extended to: Multi-pack and gift sets Barrel-proof and limited editions Ready-to-drink cocktails International liquor retailers The logic adapts as new retailers and naming conventions are added.
Conclusion
SKU name inconsistency is one of the biggest hidden blockers in liquor price intelligence. Without normalization, data remains fragmented and insights remain unreliable. Through structured attribute extraction, unit standardization, rule-based matching, and controlled fuzzy logic, Food Data Scrape transformed messy, retailer-specific product listings into a unified master catalog. The result was not just cleaner data, but trustworthy intelligence that brands, retailers, and analysts could confidently act on. In liquor analytics, normalization is not a backend task. It is the foundation of every decision that follows.