The Client
Our client, a key player in the grocery delivery industry, utilized our Shipt grocery delivery data scraping services to bolster their operational capabilities. By harnessing valuable insights from Shipt's practices, they aimed to refine their delivery operations and stay competitive in the dynamic landscape of the grocery delivery business.
Key Challenges
Dynamic Website Structure: Shipt's website had a dynamic structure, making it challenging to design a scraping algorithm that could consistently navigate various HTML layout changes. Frequent site structure updates required constant monitoring and adjustments to ensure accurate data extraction.
Anti-Scraping Measures: Shipt implemented robust anti-scraping measures to protect its data. These measures included IP blocking, CAPTCHAs, and other security mechanisms. Overcoming these hurdles without detection demanded advanced techniques such as IP rotation, using proxies, and employing headless browsers to mimic human behavior.
Code Updates: Shipt regularly updated its website code, introducing or modifying new elements. Our scraping code needed to be agile and adaptable to these changes. Regular maintenance was essential to keep the scraping script functional and avoid disruptions in data collection.
The volume of Real-time Data: Shipt's real-time data, including delivery schedules, order statuses, and inventory presented a significant volume for scraping, managing, and processing this large dataset in real time, which required efficient data storage, processing, and retrieval mechanisms to prevent bottlenecks and ensure timely analysis.
Session Management: Maintaining stable and persistent sessions during scraping sessions was critical for collecting coherent datasets. Shipt's security measures, including session timeouts and token-based authentication, required careful handling to prevent disruptions in the scraping process.
Key Solutions
- Our grocery delivery data scraping services implemented a dynamic scraping algorithm that utilized advanced techniques such as XPath selectors and CSS selectors, allowing the script to adapt to changes in the HTML structure. Regular monitoring and updates ensured the algorithm remained effective while scraping Shipt grocery data.
- We employed IP rotation and a pool of proxies to bypass anti-scraping measures. Additionally, we integrated headless browser technology, mimicking human interaction patterns to avoid detection. Utilize CAPTCHA-solving services to handle any challenges Shipt's security mechanisms pose.
- We established a robust version control system and an agile development approach for Shipt grocery delivery scraping. Continuous monitoring of Shipt's website for code changes enabled us to update our scraping script promptly. Automated testing was employed to ensure the script's functionality after each update.
- We optimized our data storage infrastructure to efficiently handle large volumes of real-time data. Distributed computing and parallel processing techniques were employed to enhance data processing speeds, ensuring timely analysis of the extensive datasets.
- We implemented a robust session management system that could handle Shipt's session timeouts and token-based authentication. Persistent sessions were maintained using session tokens, ensuring uninterrupted and coherent data collection during scraping sessions.
Methodologies Used
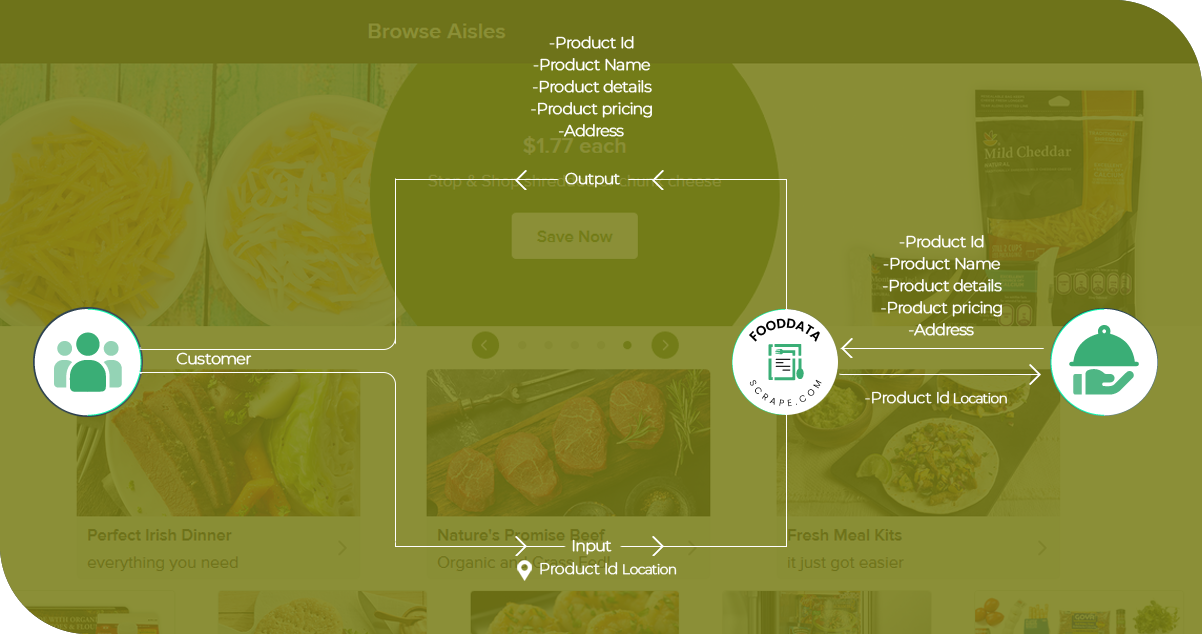
- Dynamic HTML Parsing: We employed dynamic HTML parsing techniques to navigate Shipt's frequently changing website structure. Using libraries such as Beautiful Soup or lxml in Python, our scraping script adapted to variations in the HTML layout, ensuring consistent data extraction.
- Headless Browsing: Our grocery data scraper utilized headless browsers like Selenium to bypass anti-scraping measures and simulate human interaction. It enabled our script to interact with Shipt's website just like a regular user, minimizing the risk of detection and ensuring a seamless scraping process.
- IP Rotation and Proxies: To overcome IP blocking and enhance anonymity, we implemented IP rotation and utilized a pool of proxies. This strategy helped us distribute requests across IP addresses, preventing rate limiting and ensuring continuous data collection.
- Regular Expression (Regex) Matching: Regex patterns were employed to extract specific data patterns from the HTML source code. This flexible approach allowed us to target and capture relevant information, even when embedding the data within complex structures on Shipt's web pages.
- Automated CAPTCHA Solving: Given Shipt's security measures, we implemented automated CAPTCHA-solving services to handle any challenges posed during scraping sessions. It ensured the uninterrupted flow of data extraction without manual intervention.
- Session Management: We implemented effective session management to handle session timeouts and token-based authentication on Shipt's platform. It involved maintaining persistent sessions using session tokens, ensuring a seamless and uninterrupted scraping process.
- Rate Limiting Strategies: We carefully monitored and adjusted scraping speeds to comply with Shipt's rate-limiting thresholds. Implement throttling mechanisms to control the frequency of requests, preventing our IP address from triggering rate-limiting measures.
- Data Validation and Cleansing: To enhance the quality of the scraped data, we implemented validation checks and cleansing processes. It ensured the extracted information was accurate and reliable, minimizing errors and inconsistencies in the collected dataset.
Advantages of Collecting Data Using Food Data Scrape
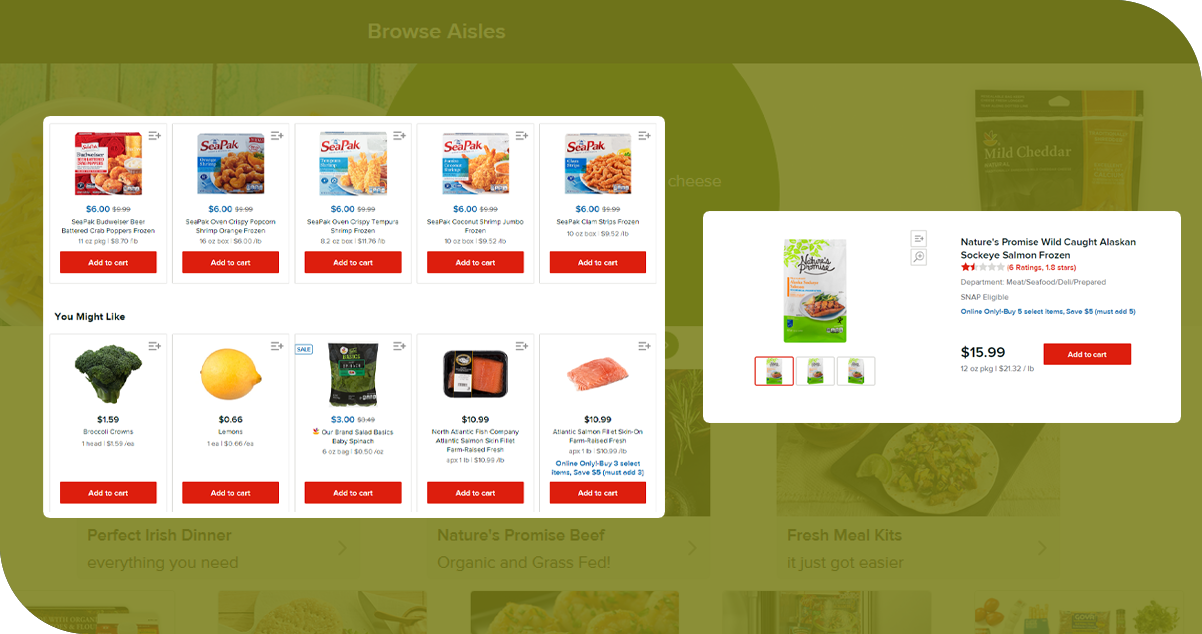
Accuracy and Reliability: This company ensures accurate and reliable data extraction. Their expertise in navigating various website structures and handling complex data ensures high-quality, error-free results.
Efficiency and Time Savings: We use advanced tools and techniques to extract large volumes of data efficiently. It saves significant time compared to manual extraction, allowing businesses to focus on analyzing and utilizing the data rather than spending time on the extraction process.
Customized Solutions: Food Data Scrape can tailor their services to meet business needs. Whether it's extracting data from specific websites, APIs, or databases, they can provide customized solutions based on client requirements.
Compliance with Legal and Ethical Standards: The company knows legal and ethical considerations related to web scraping. They ensure compliance with the terms of service of the target websites and adhere to legal standards, mitigating the risk of legal issues.
Handling Complex Websites: Food-related websites often have dynamic content, complex structures, and anti-scraping measures. The company has the expertise to handle these challenges, ensuring successful extraction even from the most intricate websites.
Scalability: scraping services can scale their operations to handle large-scale data extraction projects. Whether you need to scrape data from a handful of websites or many sources, scraping companies can adapt to the scale of your requirements.
Data Quality Assurance: We implement quality assurance measures to ensure the accuracy and consistency of the extracted data. Validation checks and cleansing processes are often part of their service to deliver high-quality datasets to clients.
Frequent Updates and Maintenance: Websites frequently change structure and content. This company monitors and updates its scraping scripts to adapt to these changes, ensuring the data extraction process remains effective over time.
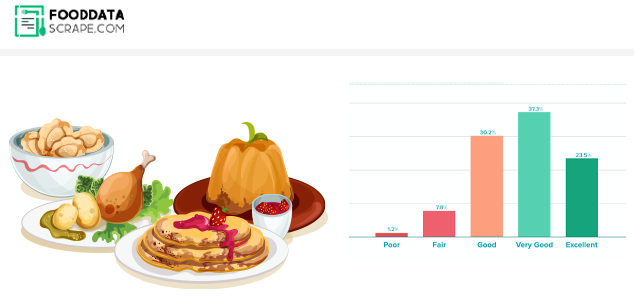
Final Outcome: We successfully scraped Shipt grocery data and empowered our client to optimize delivery operations. Our insights facilitated strategic improvements by analyzing variables like delivery times and order fulfillment rates. The data-driven approach enhanced Shipt's efficiency and contributed to an overall streamlined and optimized delivery process for our client, resulting in a more effective and customer-centric service.