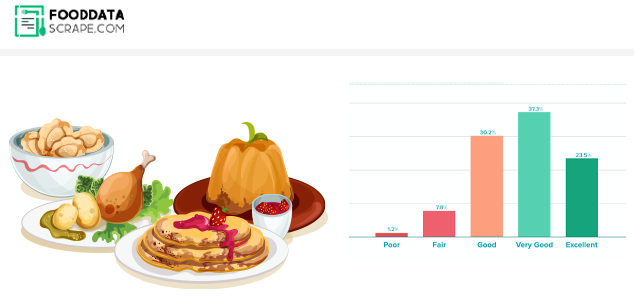
Big Data has played a significant role in influencing several businesses, including the restaurant industry. As the restaurant is very competitive, offering something fresh and different is easier to stand out. Big Data can provide eateries with a better understanding of competition and consumer preferences. Restaurants can now quickly examine the most trending items, create a client base, and obtain fast service feedback more accessible than ever before due to review sites' popularity and delivery apps.
How Do Websites Scrape Restaurant Data?
crawling and scraping of restaurant data is done using web scraping. It utilizes software to scrape public information from websites automatically. Data is collected from several websites and then presented on the spreadsheet for further study. Restaurants crawl social media sites and Google Analytics to understand their core demographics, effectiveness, and flaws in their social media operations. A reliable web scraping tool is the best option for collecting massive data.
How Can Web Scraping of Restaurant Data Boost Your Business?
Identify Ideal Customer Base: Easily target the client based on their age and interests using restaurant demographics. Enhance the experience of those demographics by using restaurant data insights.

Enhance Menu Efficiency: You can search for locations and keywords by scraping Google places. Quickly locate the competitors nearby by tracking specific cuisine or dishes. By scraping any website, you can also track the restaurant sales data on the menu, indicating the highest and the lowest sales. By scraping the competitor’s menu data, you can easily adjust to grab more profits.

Data Fields Scraping with Food Data Scrape
- Restaurant Name
- Type
- Address
- City
- Contact Information
- Food Menu
- Offers & Discounts
- Menu Images
- Working Hours
- Reviews
- Ratings
Steps to Crawl and Scrape Restaurant Data Using Python
After understanding the basics and importance of web scraping restaurant data, let’s delve deep into how to crawl restaurant data using Python.
There are several American fast food and restaurant chains spreading at a fast pace. Today, we will scrape data from some of the well-known restaurants. We will here make use of Python Selenium to search the web and crawl data for the below-mentioned restaurant data:
- Starbucks
- McDonald’s
- Subway

Crawling Starbucks Stores
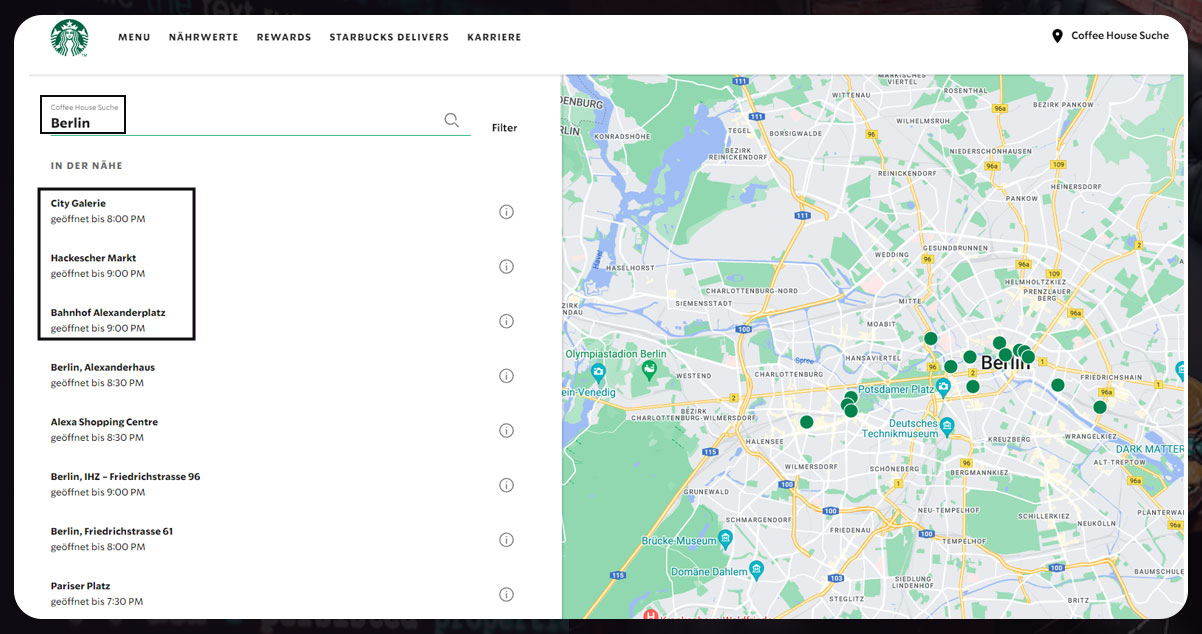
To scrape Starbucks restaurant data, first, we will analyze the Starbucks store finder website.
https://www.starbucks.de/store-locator?types=starbucksThe above website will offer a search functionality to locate stores. We will enter Berlin and find some results. We will go step-wise and mention all the addresses manually. However, we will automate the process with the help of Python Selenium.
We will navigate through our browser using Selenium and Python and automate it. Let’s start with importing.
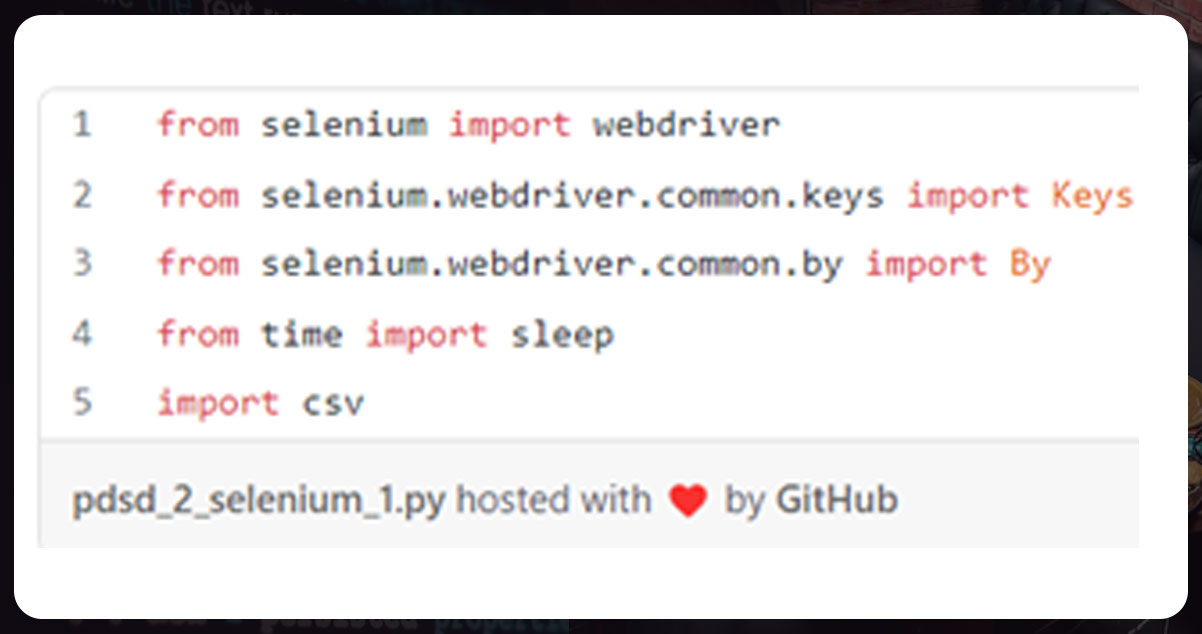
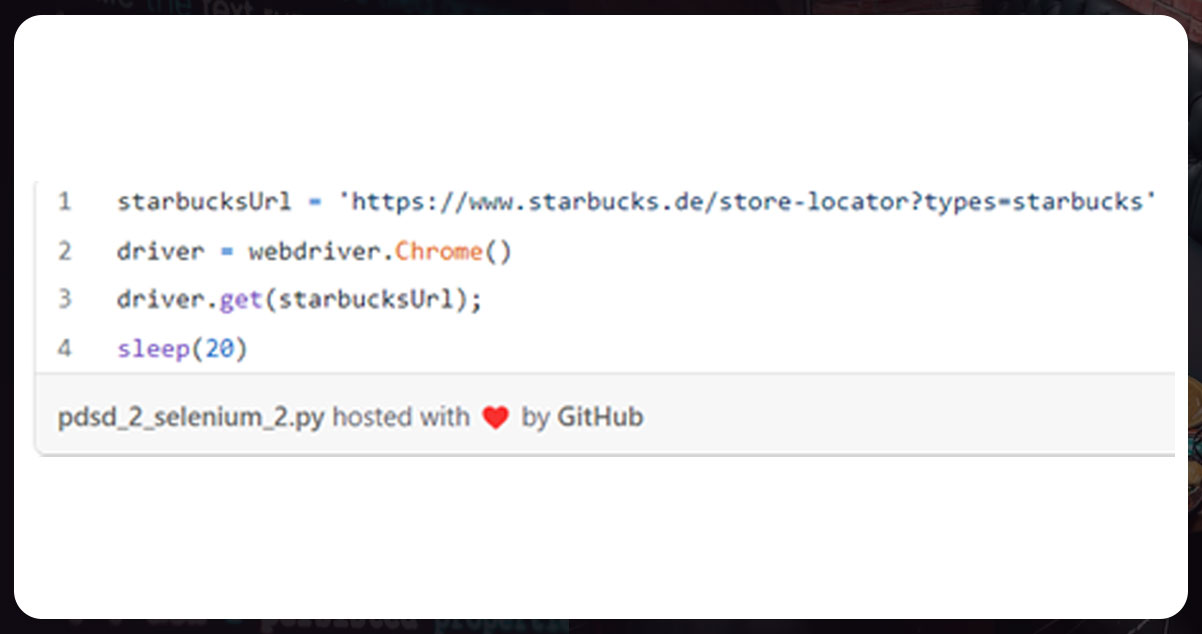
After the imports, we will define the URL in line 1, start the web driver in line 2, and then open the Starbucks URL in line 3. We will wait for some minutes to load the complete page.
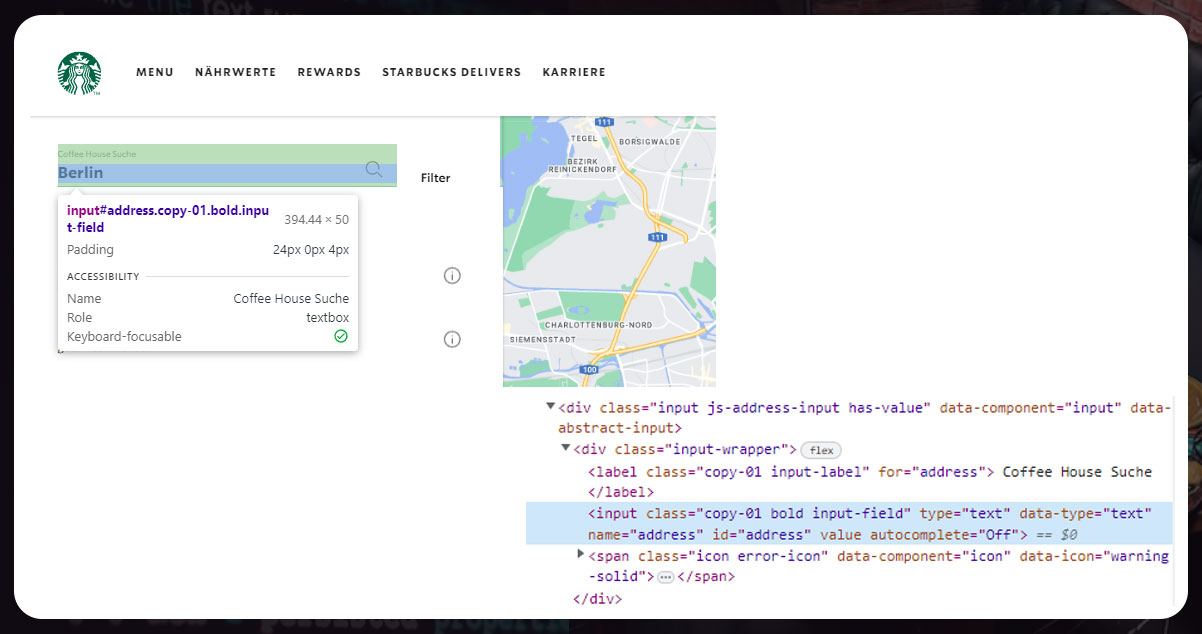
A list of Starbucks stores available in Berlin displays. Further, we will inspect and will find out that each item is addressable using

But we need help in finding addresses. So, to find it, we will execute three significant steps:
1. Click the info button:

2. Note down the address
3. Click the Exit button to get the result list.
Now, automate this.
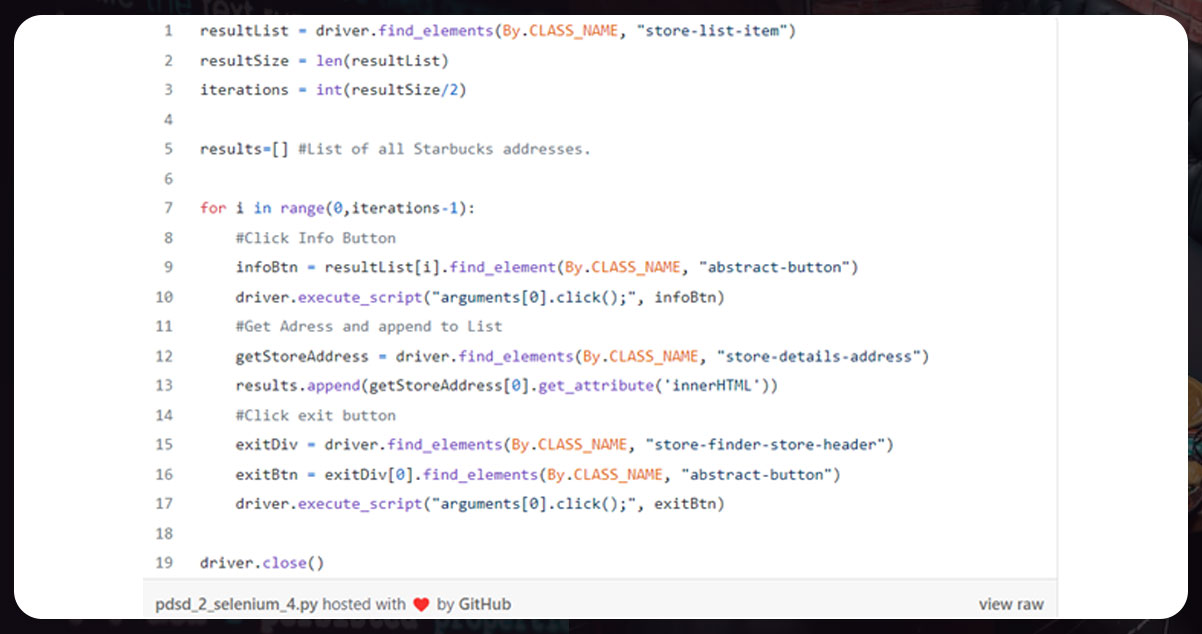
On the Starbucks page (line1), we will search for the list of items
class='store-list-item'The class is used twice for each element. We first divide it into two lines. We create an empty list additionally to hold all addresses.
In the loop 7-17, we will
- Find and click the Info button in lines 8-10
- Track the addresses and append to the list ‘results’ in lines 11-13
- Click the exit button to return to the result lists.
- Then, we will close the web driver.
We will then loop the data to save it into the CSV files.

Finally, we have all Starbucks addresses in our file
reataurants.csv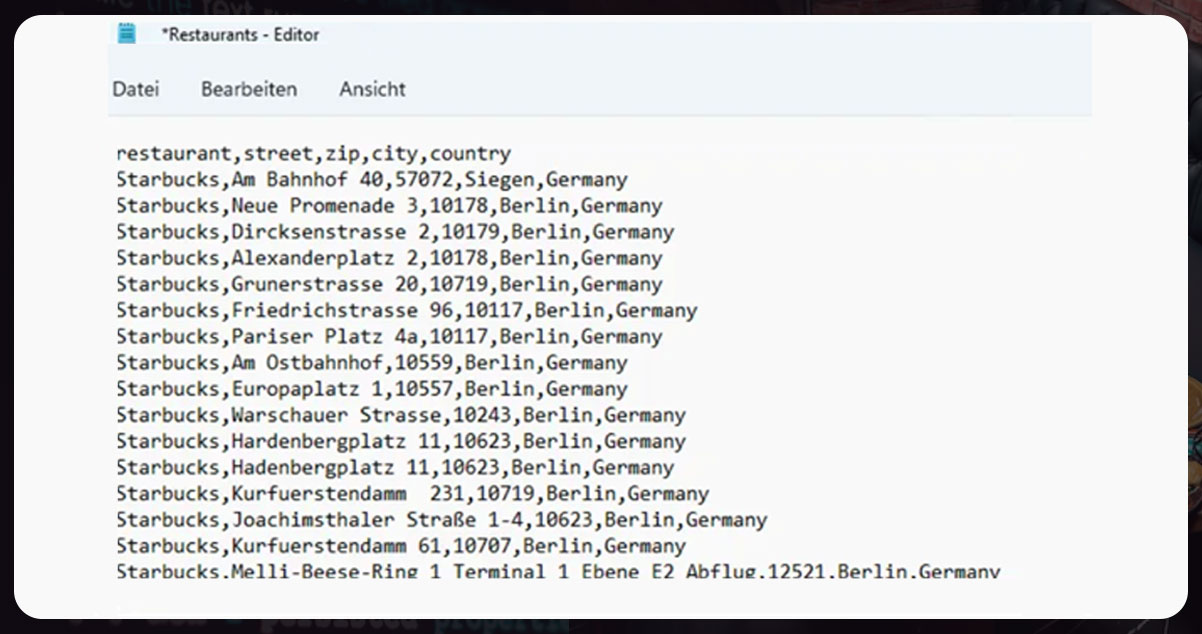
Crawling McDonald’s Restaurantt
The below page link possesses McDonald’s restaurant lists in Berlin. Now, let’s start with scraping McDonald’s restaurant data.
https://www.mcdonalds.com/de/de-de/restaurant-suche.html/l/berlin
The addresses are available within (li) with class,
class='ubsf_sitemap-location-address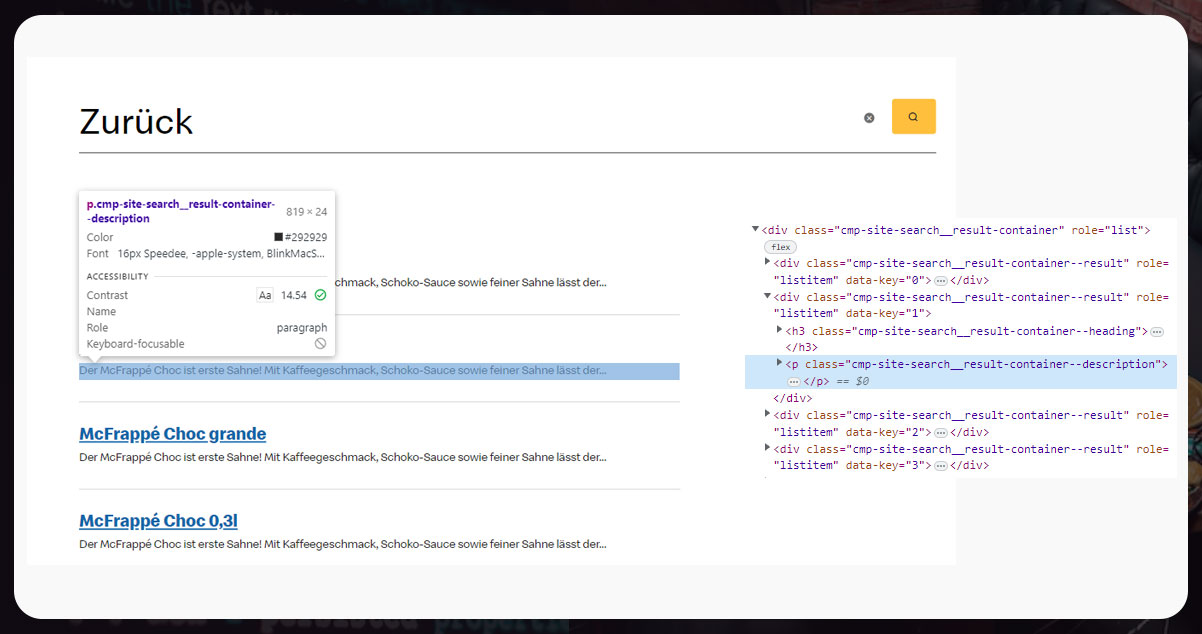
Now, automate and crawl it using Python Selenium.
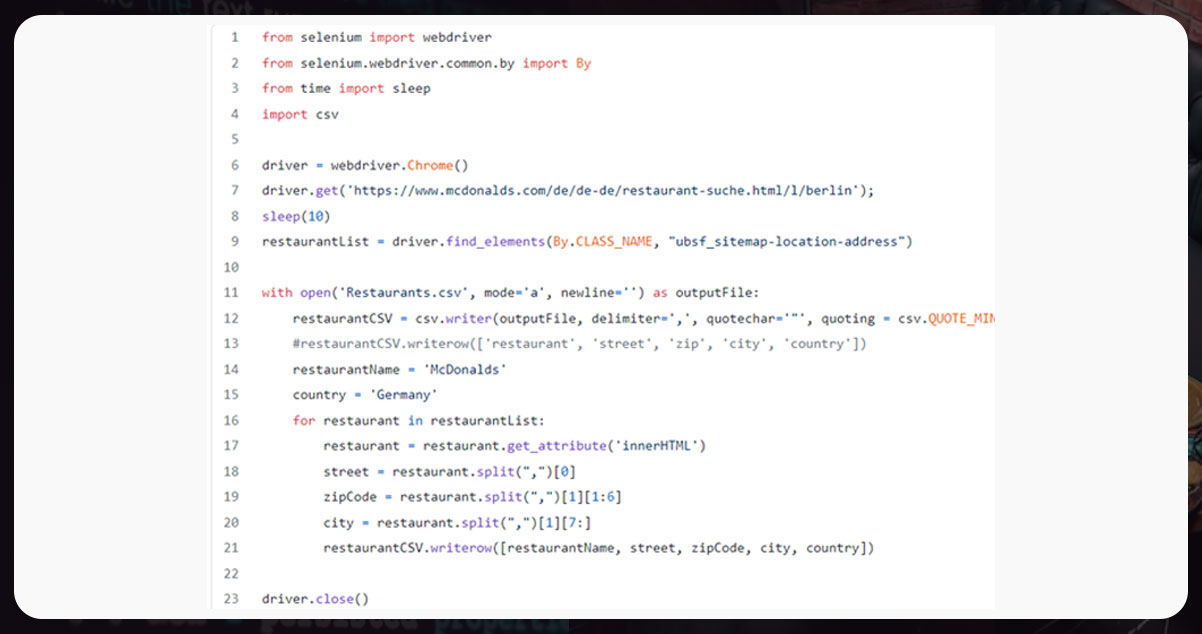
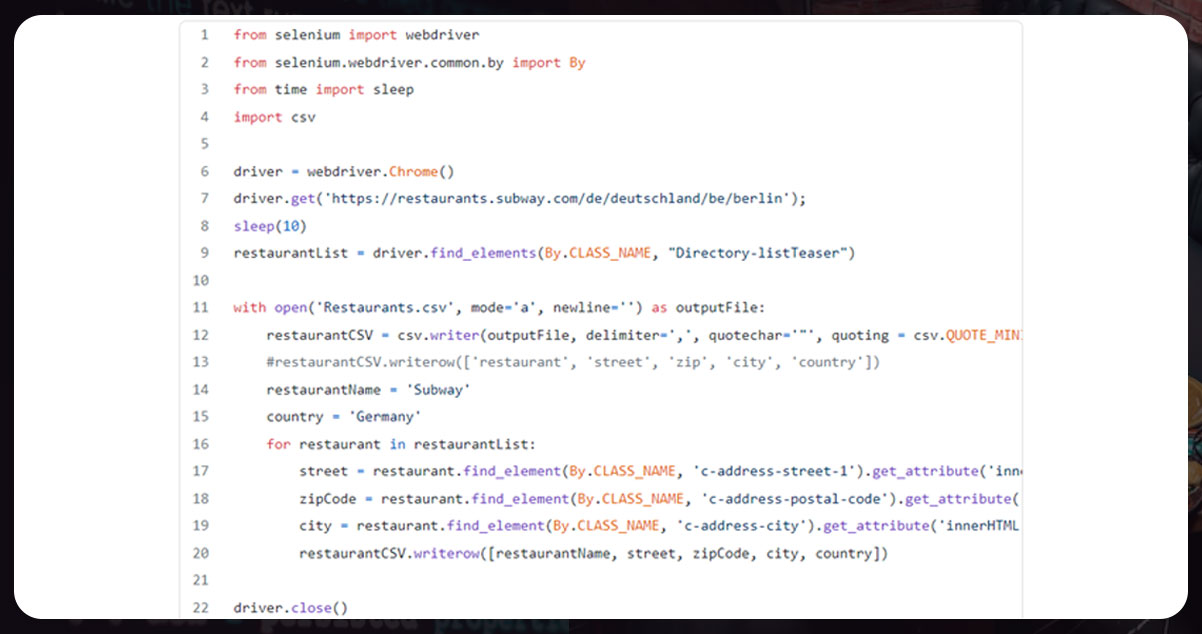
From the above code, we can say that,
- We import Selenium, time, and csv.
- The elements with class hold the address line 9. So, we select them and save them in restaurantList.
- We then open Restaurants.csv, loop through the restaurantList, and get the content into each restaurant’s street, city, and Zip code.
- Lastly, we close the web driver.
We now have all the McDonald’s addresses available in restaurants.CSV.
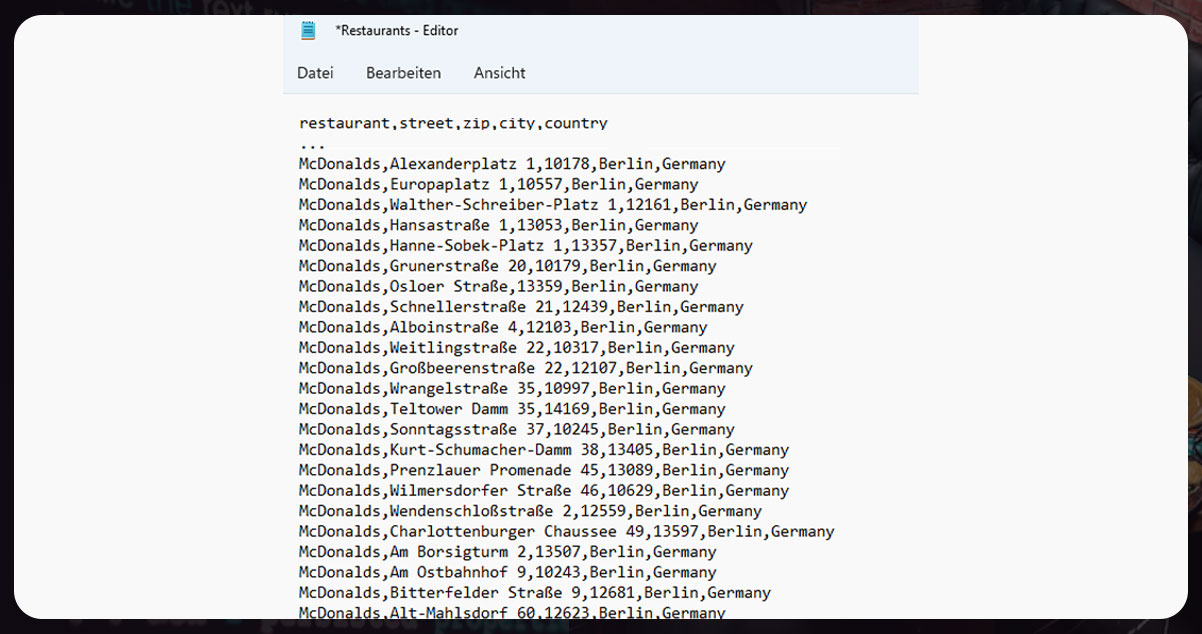
Crawling Subway Restaurants
Before scraping Subway restaurant data, inspect the Subway site for restaurants in Berlin
https://restaurants.subway.com/de/deutschland/be/berlinEach restaurant is within a list of an item
class='Directory-listTeaser'- Street is within
class='c-address-street-1' - Zip Code is within
class='c-address-postal-code' - City is within
class='c-address-city'
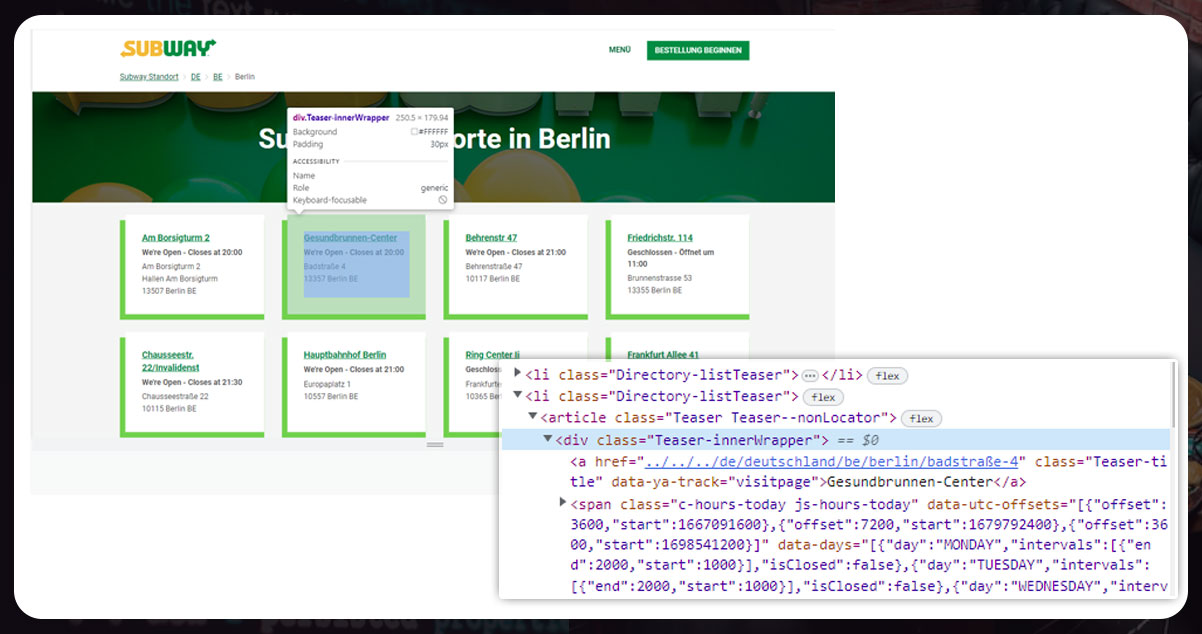
So, let’s have a code:
After running the crawler, the Subway restaurant addresses are available in our
reataurants.csv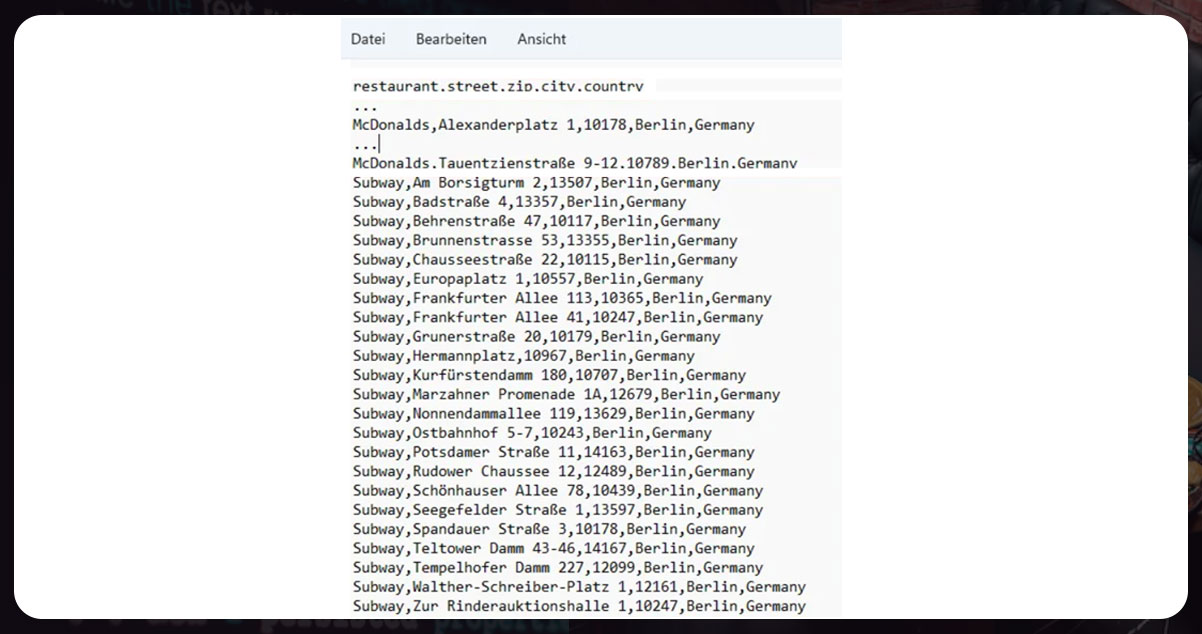
Summary:
Thus, we have done scraping for a complete list of selected restaurants and their addresses in Berlin. The above blog shows how we have done crawling for restaurant data.
To achieve this, you have to install Selenium with Python. Additionally, you also need to install a web driver.
For more information, contact Food Data Scrape now! You can also reach us for all your food data scraping and mobile app reataurant data scraping requirements.