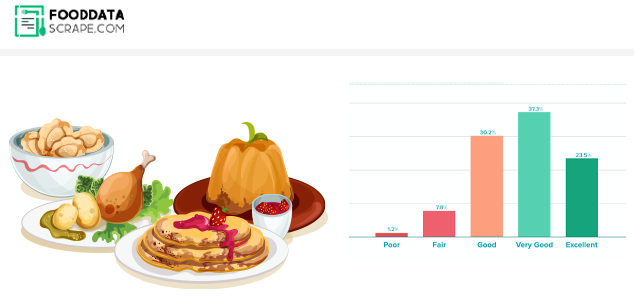
The Client
The client is a rapidly scaling alcohol marketplace aggregator operating across multiple US states with interest in competitive benchmarking and dynamic pricing. Using Saucey Beverage Data Extraction API in USA, they needed data accuracy and consistency covering product variations across different stores and delivery zones. After deployment of Liquor Data Extraction API from Saucey USA, the organization integrated new rules, dashboards, and automated pricing triggers that reduced operational dependency on manual sourcing activities. As their product library expanded into spirits, wine, beer, seasonal categories, and limited-edition brands, Liquor Product Database Scraping from Saucey USA ensured every data point remained updated, traceable, and aligned with live market demand, helping them scale faster.
Key Challenges
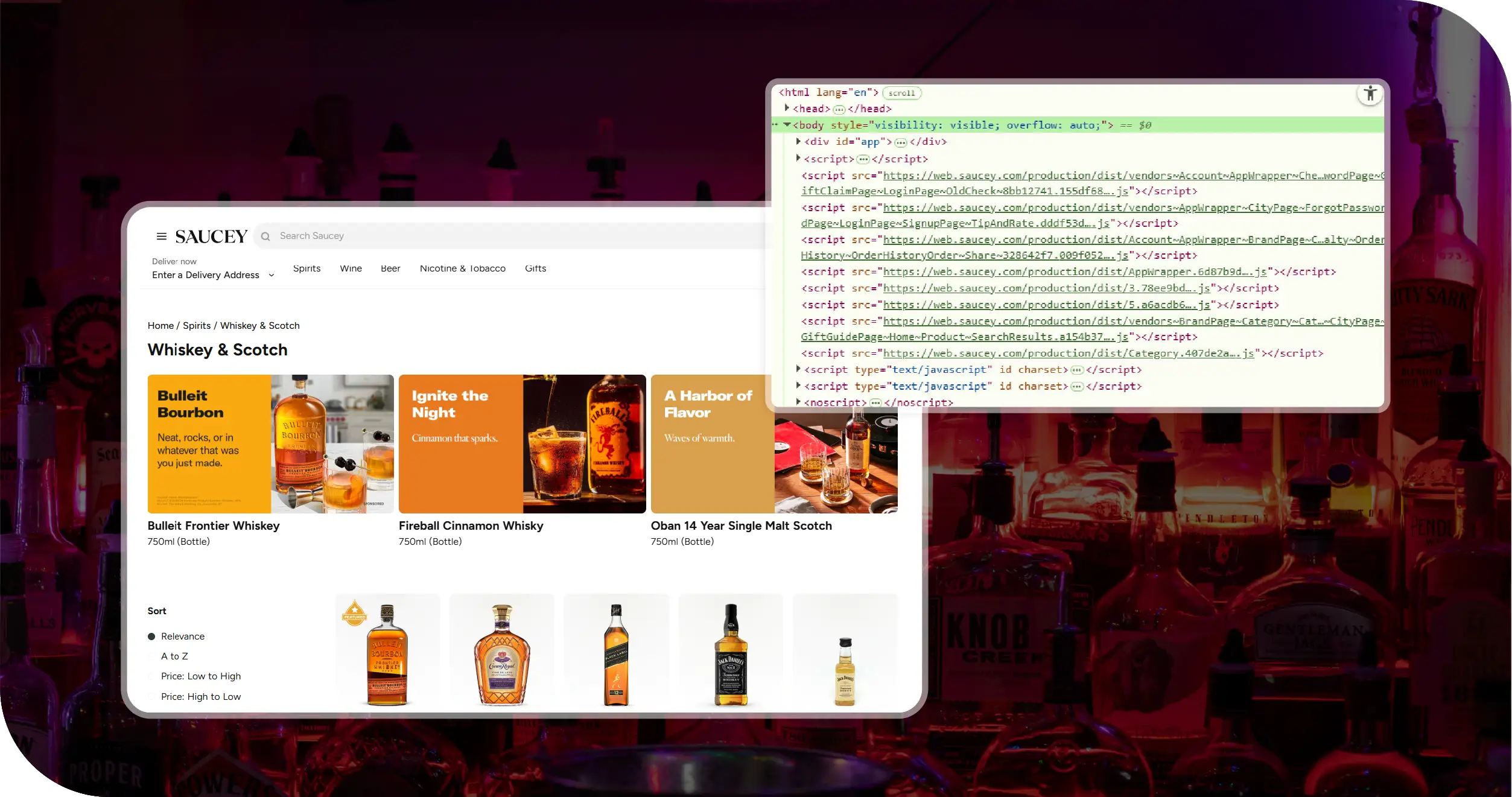
- Data Freshness
The challenge was ensuring real-time availability and pricing synchronization while using method to Extract API For Saucey Liquor Prices to reflect accurate numbers across multiple store regions and constantly changing inventory environments. - Regional Variations
Price variations across delivery zones made structured tracking difficult, especially while interpreting territories and store-level differences documented inside Saucey Liquor Prices Dataset. - SKU Normalization
Inconsistent naming standards and missing product classifications required mapping, validation, and cleaning while attempting to Scrape Saucey Liquor Data with accuracy.
Key Solutions
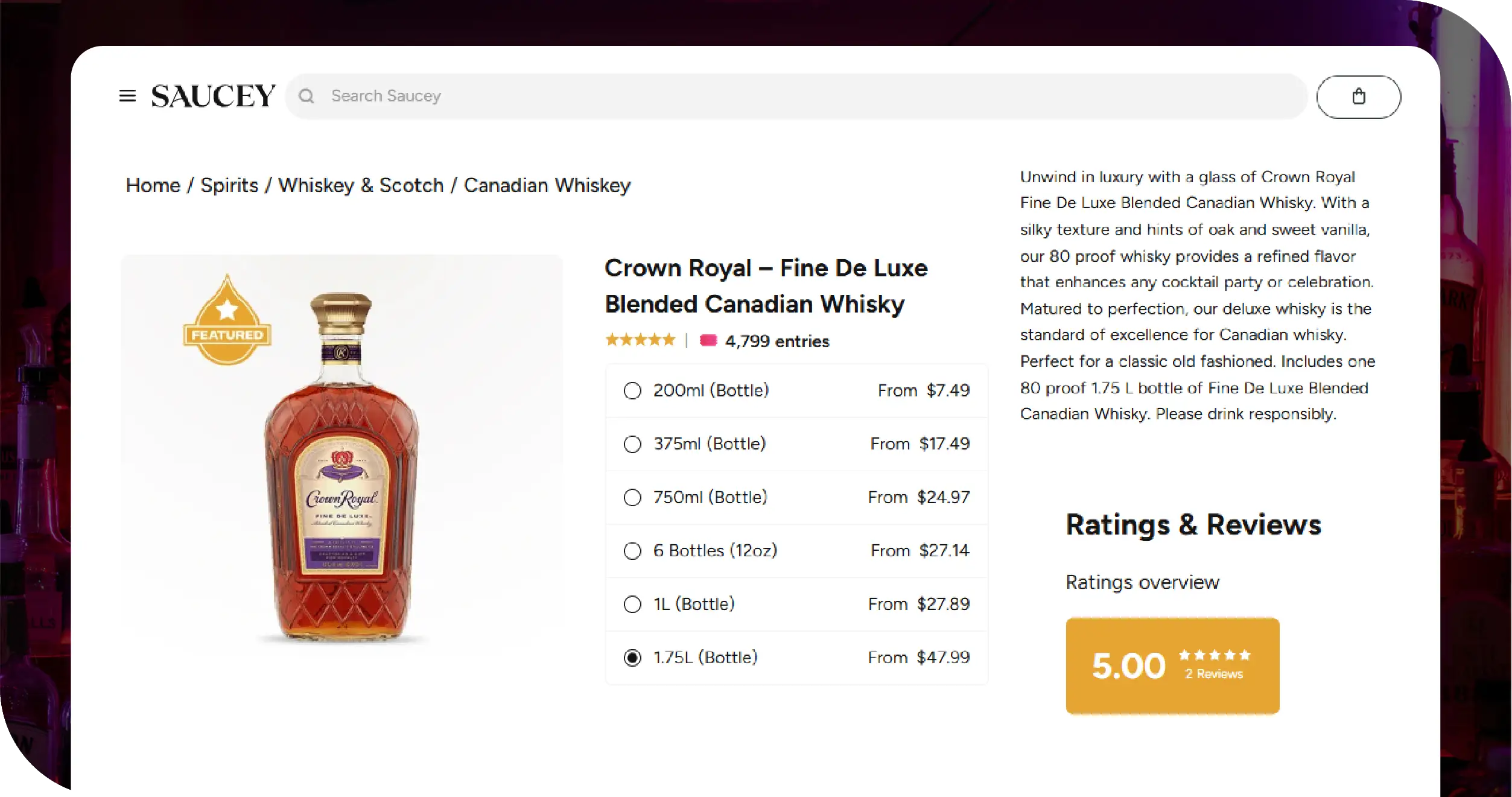
- Automated Price Tracking
We deployed frameworks to detect fluctuations, apply mapping rules, and continuously Extract Alcohol Prices Data across multiple catalog segments while ensuring compliance and normalization. - Scalable Scraping Framework
Dynamic crawlers were integrated through Liquor Price Data Scraping Services to handle multiple products, region-specific labels, and promotional discrepancies. - Unified Data Warehouse
All extracted pricing was stored, tagged, and version-controlled for future analytics, enabling powerful search filters across growing Alcohol and Liquor Datasets.
Sample Scraped Dataset Table
| Product Name | Category | Volume | ABV% | Price | Region | Availability |
|---|---|---|---|---|---|---|
| Tito’s Vodka | Vodka | 750ml | 40% | $21.99 | California | In Stock |
| Crown Royal Apple | Whisky | 750ml | 35% | $27.49 | Texas | Instock |
| Moët & Chandon Brut | Champagne | 750ml | 12% | $59.99 | Florida | Limited |
| Jack Daniel’s Honey | Whiskey | 1L | 35% | $33.50 | New York | In Stock |
Methodologies Used
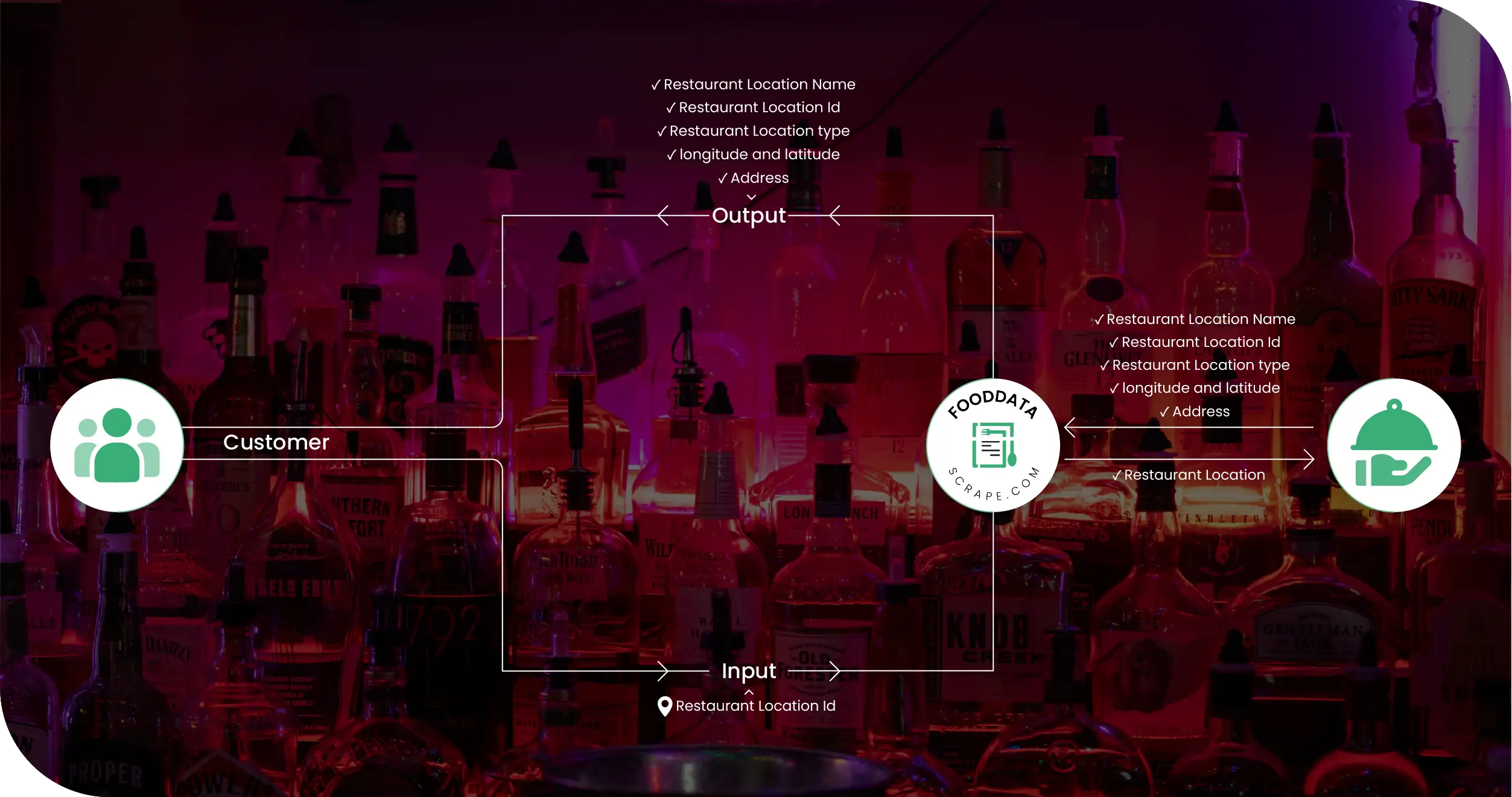
- Data Mapping Rules
We implemented structured product tagging and classification layers. This ensured consistency across different store-level variations and brand naming formats. The methodology reduced duplication, improved recognition accuracy, and established standardized models usable for analysis, crawling, extraction, indexing, and business rule automation. - Dynamic Locator Crawling
We used adaptive crawling logic capable of detecting location-based differences, category structures, and pagination patterns. This ensured the scraper stayed operational even when UI elements, navigational layouts, and pricing blocks were updated, redesigned, or hidden behind interactive modules such as tabs and dynamic loaders. - Automated Validation
AI-driven validation ensured every extracted field met business rules. Missing fields were automatically enriched through pattern recognition. The system flagged inconsistent pricing for review, improving accuracy and reducing repeated processing. This ensured trustable datasets ready for dashboards and predictive business forecasting. - Continuous Sync Routines
The crawlers operated on scheduled intervals to reflect live platform changes. This reduced latency and guaranteed that pricing comparisons, inventory flags, discount recognition, and historical versions remained synchronized. The methodology was key for monitoring updated listings accurately across multiple operating hours and shifting store-level policies. - Compliance & Data Governance
We followed best practices using secure data processing and metadata retention rules. Authentication layers protected extraction operations, and all stored data was governed with access controls, logging checkpoints, and traceability to ensure complete transparency and regulatory alignment across internal and external use.
Advantages of Collecting Data Using Food Data Scrape

- Faster Decision Making
Clients gained the ability to evaluate competitive pricing instantly. The automation eliminated outdated reports and manual checks, enabling teams to adjust strategy, offer discounts, or run promotions faster than ever. This speed advantage created measurable revenue and operational improvements. - Higher Data Accuracy
Automated structures significantly reduced human error. Every extraction run provided clean, dependable, and high-quality data aligned with store-level realities. With continuous verification, pricing was correct at the SKU level, enabling reliable analytics and confident decision making across leadership and technical teams. - Improved Competitiveness
Clients stayed ahead of market shifts, seasonal inventory cycles, and regional promotions. The visibility allowed teams to refine pricing and product placement strategies, capturing stronger market share while reducing revenue losses from outdated pricing assumptions and delayed benchmarking processes. - Operational Efficiency
Analysis workflows became effortless with structured datasets. The availability of standardized taxonomies, enriched product metadata, and automated reporting pipelines allowed reduced workload and minimized time spent on research, cleansing, and manual spreadsheet maintenance across pricing and merchandising departments. - Long-Term Scalability
The system expanded effortlessly as new categories, brands, or market zones were introduced. Centralized processing and configurable logic enabled fast onboarding without redevelopment. This future-ready capability ensured long-term usability and operational sustainability across multiple scaling phases.
Client’s Testimonial
“As a brand scaling alcohol retail intelligence, data accuracy was critical to our growth. Before automation, pricing research took days, and discrepancies slowed our decision-making. After integrating the solution, reporting became instant, reliable, and available in formats our teams use daily. The system dramatically improved forecasting, compliance alignment, and operational efficiency. We now make faster decisions, negotiate better with distributors, and confidently adjust prices at scale.”
Director, Pricing Strategy
Final Outcome
With our automated extraction engines, the client can now seamlessly Scrape Alcohol Price Data across multiple cities and product formats with zero operational dependency. By deploying scheduled crawlers and structured classification logic, the data pipeline became stable, repeatable, and fully connected with their internal workflows, producing actionable insights through a unified Liquor Price Tracking Dashboard. Over time, the ability to identify trends, forecast demand, and benchmark inventory improved financial visibility and enhanced competitive advantage. The dataset served as a reliable foundation for machine learning, pricing automation, forecasting models, and category expansion supported by our scalable Liquor Data Intelligence Services infrastructure.