The latest technique for obtaining Internet data is called web scraping. The term describes the advanced method of visiting websites and obtaining specific data, such as pricing. Marketing, business, and consumer price index measurement are just a few of the industries currently using Web scraping, enabling the creation of large, customizable data sets at minimal cost for research and commercial purposes.
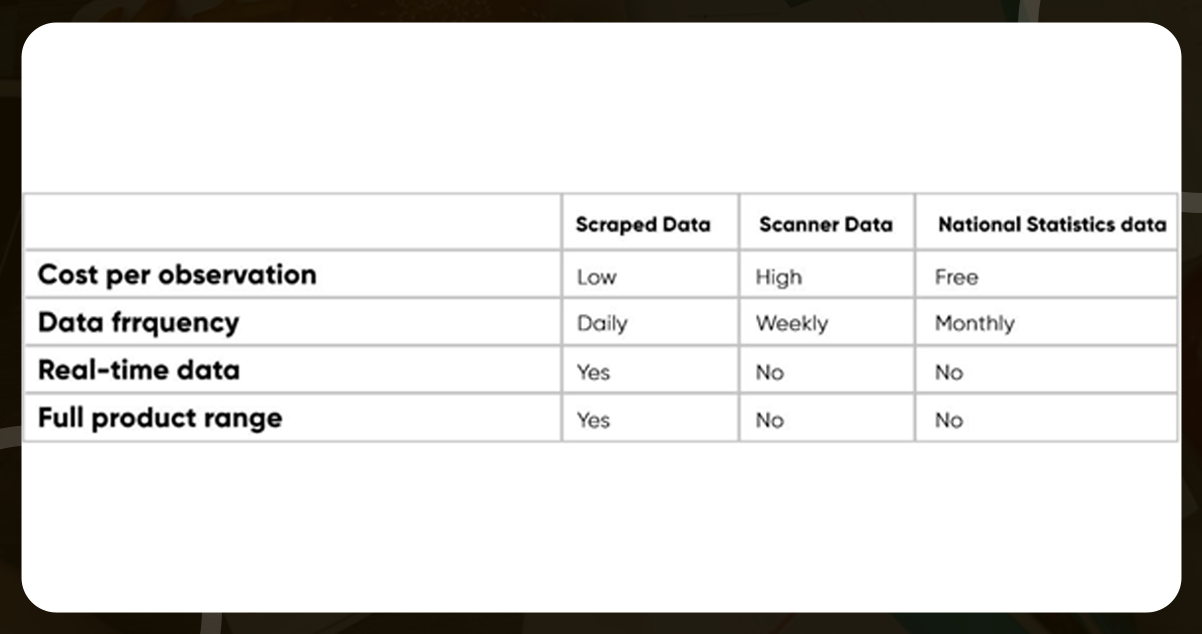
Food price research needs to pay more attention to data extraction procedures. We generally depend on more traditional consumer expenditure datasets, such as government pricing indexes and retail scanner reports, for agricultural investing and food production analyses. There are still several problems with these information sources.
Building a Web Scraper Technically
There are several methods for developing a web scraper, and probably only so many strategies work for everyone. It would be best to have a script to visit the weblinks with the data, find the relevant details and the components that define elements, and then save and store them in structured records. Information about product size, customer reviews, categories, place of origin, etc., should be included.

Theoretically, the script should simulate a web user exploring several websites and collecting predefined information. This downloading must be done with delayed requests to ensure a moderate pace of traffic on the web pages. Let’s read more on how to develop a food price data scraper.
Several scripting languages include pre-programmed modules for this reason, including Python and R. While these code snippets are undoubtedly helpful as building blocks, it is always important to tailor the script to the specific web page based on the layout of the site, page layout, need for verification, etc.
Large online retail food websites offer online collections but require an interface for app programming to provide instant access to their food pricing. Since many websites contain reactive components, standard HTTP queries cannot be used. Consequently, the program must navigate and "click" across the web page using an " authentic" Internet browser.
Script installation can be fully automated once developed and experimentally validated; a scheduler will start downloading at predetermined intervals. However, small changes to a website's style, product grouping, or other elements can cause the scraper to stop. Sufficient time should also be allowed for testing and problem-solving.
The accessible data can be saved with defined components, such as text, Excel table, or CSV file (name, price, ID, timestamp, etc.). Alerts can be included to notify users of such problems, as emails can be sent when a script is incomplete or the minimum download size is reached. Read below the benefits of web scraping for food price research

What Benefits Do Web Scraping Price Data Offer?
Web scraping is a popular new technique for collecting food information for other food pricing research. It helps overcome some of the constraints of traditional sources of information like official statistics and scanner info
Low Pricing

Comprehensive data sets can indeed be pricey. Accessibility to durable and diffused data, like metadata, is expensive at the retail stage. Price acquisition via web scraping is free if done with mainstream applications. One of the drawbacks of data extraction is the hours spent learning and evaluating the programs.
There must be electricity and internet connectivity when the script is run at the designated times. If resources are available, operations can also be outsourced to various businesses providing information. With everything in place, there is a great degree of adaptability between nations and goods, effectively bringing down the unit price per observation to nearly zero.
Sampling on a Regular and Real-time Basis
The user may choose to execute and get pricing and other details biannually, every week, every day, or more regularly when the code is released (e.g., on an hourly basis, as achieved by Ellison and Ellison, 2009). Datasets published daily are sufficient for many applications while researching food prices
While compared to assessing time-aggregated pricing data, one such high sample frequency enables a more thorough investigation of price fluctuations and the use of additional analytical techniques (Edelman, 2012). Moreover, there is also no publishing lag since data is acquired on time. This is essential for predicting and assessing recent activities or new policies.
Product Types and Information
Official data often indicate consumer prices for various products or categories. Additional details, including order size, branding, qualitative distinction, and so on that might be beneficial for food pricing evaluation are typically unavailable.
Web scraping can obtain food prices for specific goods and accessible product characteristics. This material might be beneficial for answering some research topics. If not, the experts can consolidate the data to the desired level using whichever techniques they think are acceptable, utilizing this information as a preliminary step.
Type of Store
The preponderance of secondary data specifies that it was gathered at the "retail level," making distinctions among large multi-retailer chains, discount stores, and grocers. Web scraping is a technique used by researchers to identify the merchants, retailers, distributors, or online delivery services they work with and to gather pricing, if available, without any personal collection.
Obtaining an area code or choosing a nation may be necessary to access many websites in different areas and countries and may be incorporated into the web scraping application.
Customization and Transparency
Even though scanner data and associated official numbers provide consistent and organized data, such sources may only sometimes give the information that experts need for specific work. It is equally possible that this data has been collected to some extent or is not obtainable within the same structure or through the same source for all geographical areas of interest, causing minimal worldwide similarity.
The development of unique data sets suited to the user's requirements is made possible by restaurant data extraction services. With no missing elements or "black boxes," they are clear about the process used to collect the data. The research community gets consistency and clarity when open-source technology and shared codes and information are utilized. Giving researchers a choice to gather their data as part of their scientific investigations instead of depending solely on secondary resources may enhance scientific research's standard and accuracy.
Research Areas
Is Web scraping for food prices beneficial for online retailers? The online price of consumer goods other than food was examined using several web scraping queries. Most original price studies on the internet focused on products like books and electrical parts since big online retailers started with all these different products. Is food price data Scraper beneficial for online retailers? Learn more.
Scraping Retail Price Policies Through the Internet
Online publicized prices are presumably more adjustable than offline rates; however, except for occasional sales, they tend to follow relatively fixed pricing patterns. Since there are almost no expenses associated with changing menu pricing in online markets, providers may react quickly to fluctuations in supply and demand, increasing efficiency overall. Consumer price searching expenses have fallen, and rapid and easy costing evaluation for a given item is made possible in part by websites that compare prices.
A pricing system based on a review of past and present client needs, rates established by competitors, and additional variables like vacations or weather systems are possible in online shopping. Ingenious web data extraction technology that purported to log in from various Ips and with multiple user accounts would need to be used to identify such behaviors. Once more, the question is whether it is acceptable for researchers to gather data while pretending that a user has made a legitimate request.
Final Note
We showed that online scraping is a reliable and efficient data-collecting technique for researching food prices. Using web scraping to generate original data sets, it is possible to get beyond typical problems, including missing data, frequent mistakes, and sampling methods. Internet retail price rises have been the primary use due to their extensive accessibility. Web scraping info may be used to examine how prices are established in the increasing internet food retailing industry, how well this price-fixing may affect the distribution network, and how it will change global food networks.
You can contact Food Data Scrape immediately or ask for a quotation if you want more information about how food web scraping and mobile grocery app scraping services are utilized for food price research.