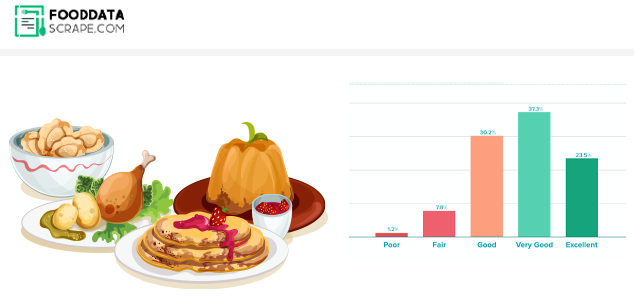
Yelp is brimming with customer reviews. These help businesses track their business's performance as their customers perceive it. The data behind these reviews require competitor research. This blog emphasizes the working of the algorithm and the steps for extracting the Yelp downloading algorithm with the help of web scraping services and the steps needed to generate a structured algorithm.
While creating a sophisticated algorithm, the following steps are needed.
Start with the basic algorithm that solves a minor problem.
Scale it up to solve multiple instances of the same problem.
Add layers of complexity to make the algorithm more complex.
After completing these processes, you can gradually add features like exploratory data analysis or insight extraction, machine learning, and visualization.
Basic Algorithm: It comprises the code used to extract data from the Yelp page and gives you an idea of the algorithm's use.
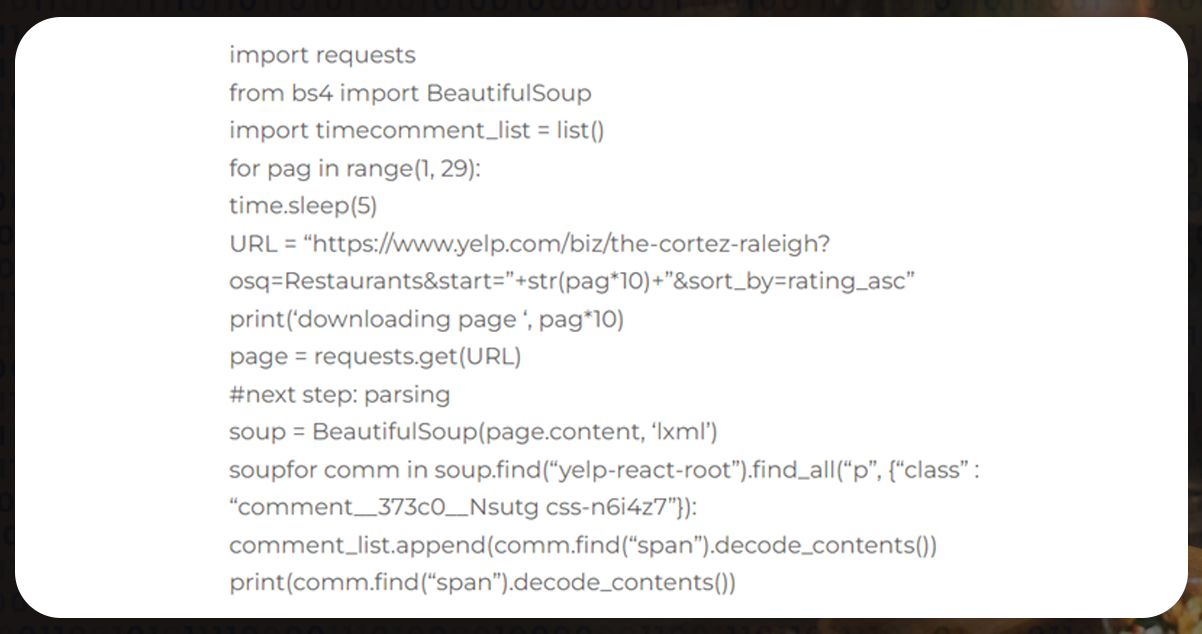
The above code is minimal and straightforward to comprehend.
Instructing the Algorithm
Develop a control panel to structure the code
It includes the list of links the algorithm will attempt to connect.
A function to control the algorithm's parameters.
Simultaneously, the algorithm is available in sections concerning the best programming procedures:
Variable addition
Importing of Libraries
Functionality configuration
Carry out the algorithm
Analyze & export the findings
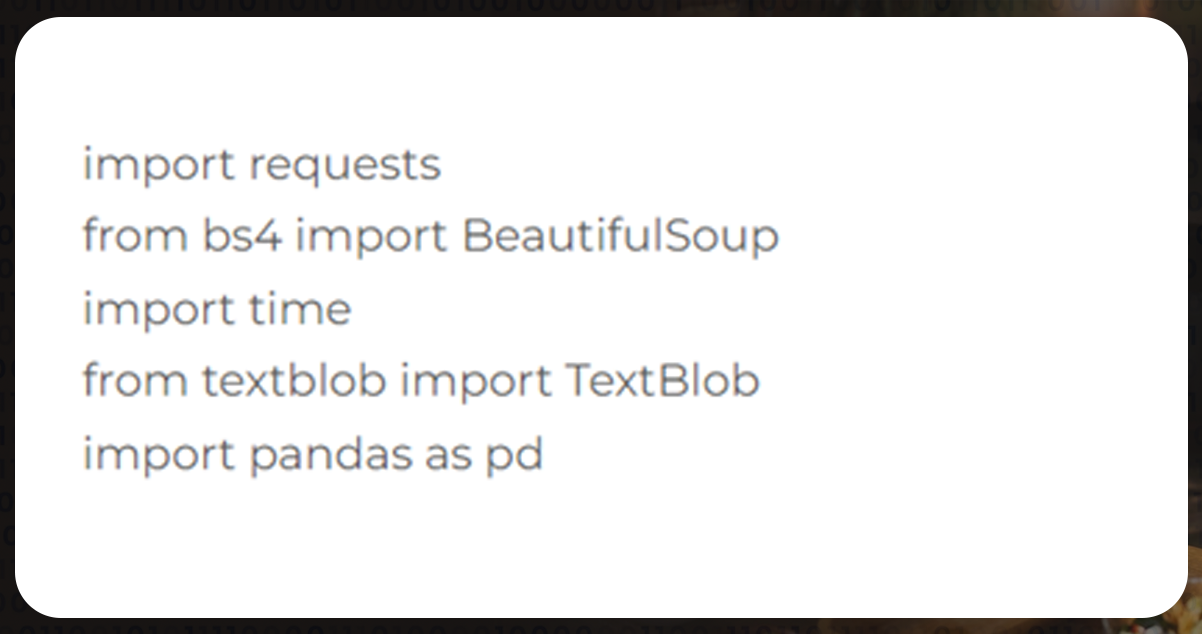
Importing of Libraries
The first step is to dedicate a small part of the code to the libraries we will use across our entire code. However, you won't be requiring pip to install anything. Because whatever is required is already available in Python.
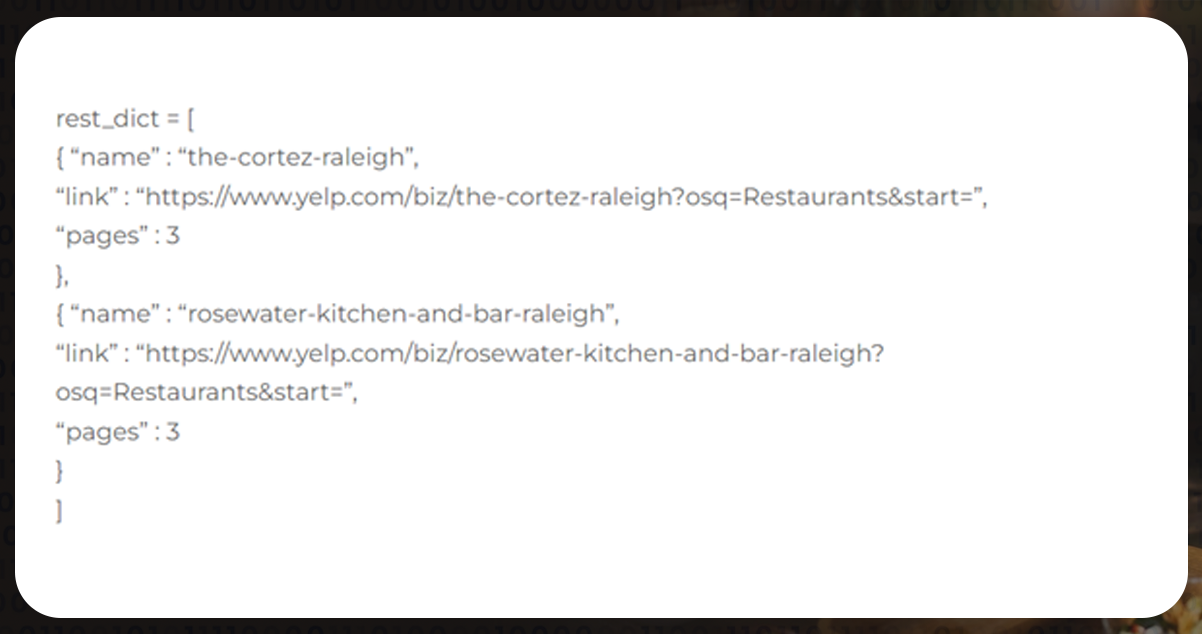
Adding Variables
Utilizing the collection settings, you can easily manage the webpage downloaded by BeautifulSoup. To build the connection, you must link each restaurant, the number of review pages you want to scrape, and the restaurant name to include in the dataset.
A stacked list or a dictionary is the best information storage approach.
Installing the Functions
If you require the code, describe every detail of the function. Download it directly, rather than compiling and pasting the distinct lines of code into your IDE. As you avail all the information, now create an algorithm.
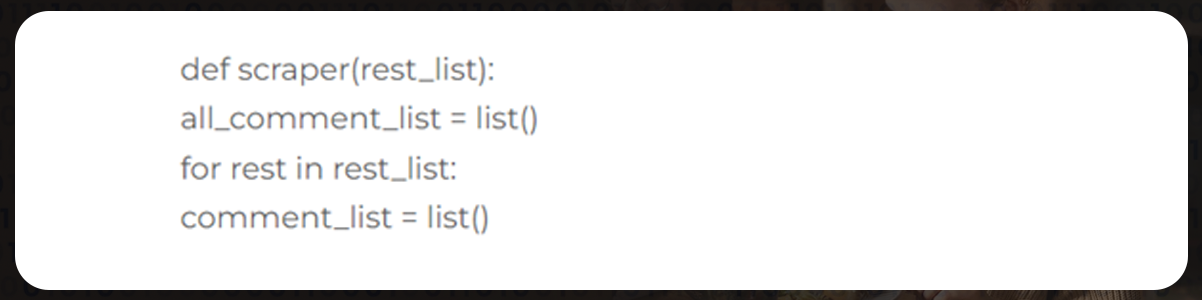
It will cycle through all of the directories in the list first:
for pag range (1,rest['pages']):Now add a try statement so that you don't need to start again in case of errors in the code or any connection problem that causes the algorithm to stop working. However, safeguarding is essential to prevent any algorithm from halting due to any web scraping fault. If it happens, you will either have to spend more time figuring out where the algorithm has stopped, or you will have to start over.
Try:
We will implement a 5-second delay before initiating a request to avoid IP getting refused. If you perform too many queries, the website recognizes that we are the robot and deny our connection request. The algorithm will show an error if we don't have a try statement,
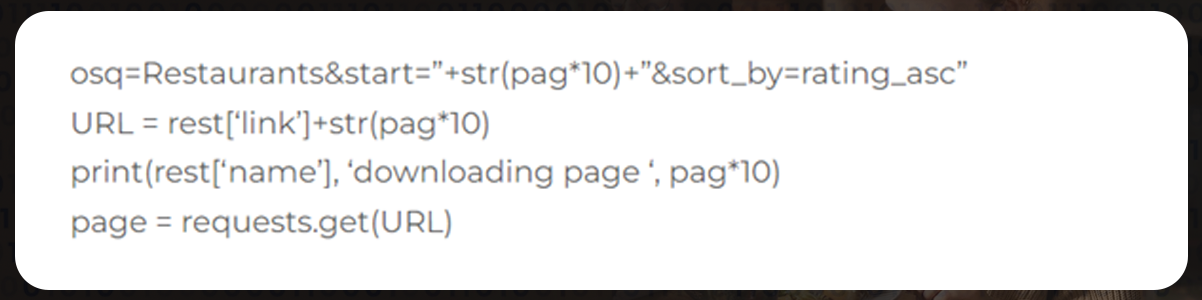
time.sleep(5)Now, copy the Yelp scraper and copy the HTML. Repeat the same for the appropriateb amount of pages.
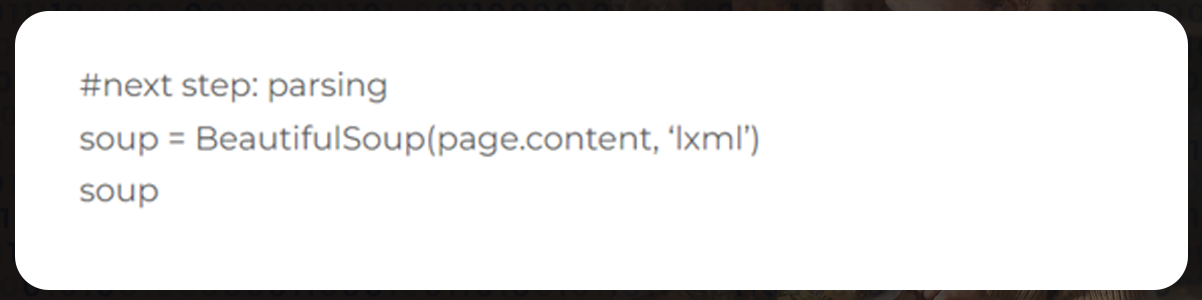
Next, convert the HTML into code for BeautifulSoup to understand. It is the only method to extract data using the library's functions.
Now, take the reviews out of these 1000-line strings. After thoroughly examining the code, we could determine where the reviews were in the HTML elements. This code will finally retrieve the content of these components to the letter.
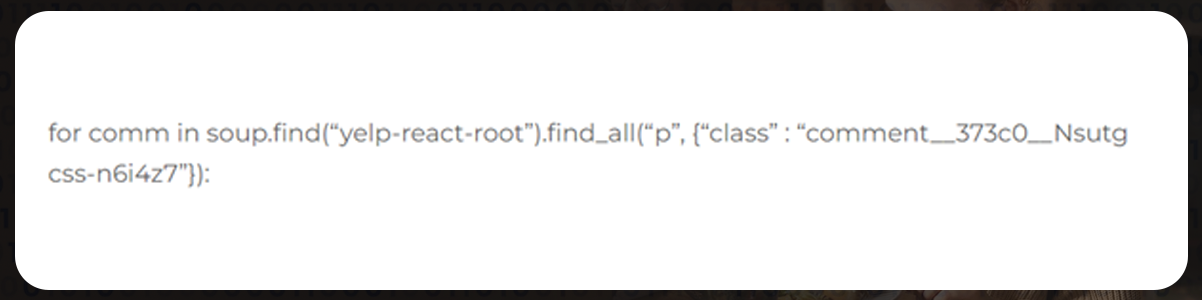
Here, we are saving a single restaurant's content in a comment list. It contains each review matched with the restaurant's name.
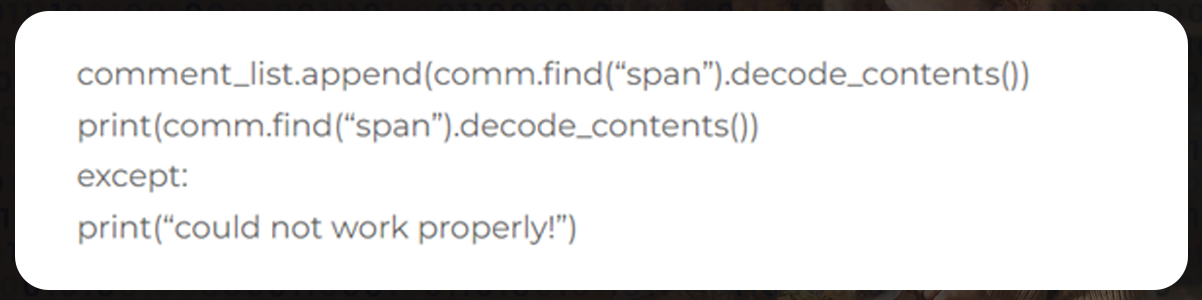
We will then save the reviews in the comment list to the general list before scraping the next page. It will reset in the following way:
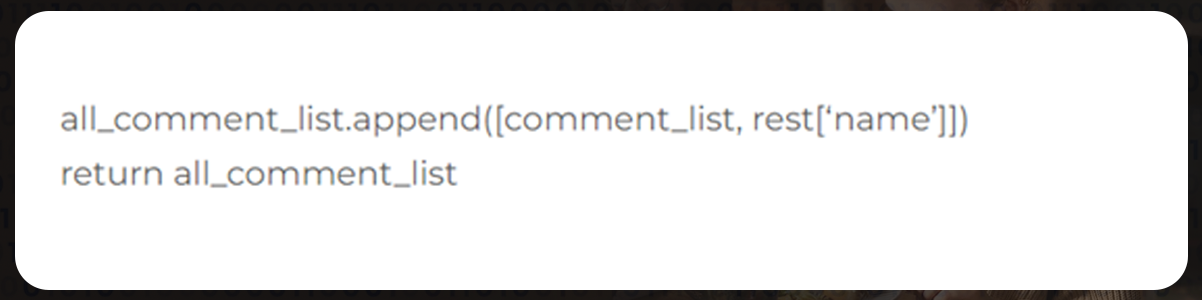
Finally, execute the algorithm with only a single line of code and save all the delivered results in the reviews list.
review = scrape(rest_dict)For more information, contact Food Data Scrape now! You can also reach us for all your food data scraping service and mobile app data scraping service requirements.