Can Selenium be Used to Scrape Food Data from the Zomato Website?
Wondering what Jakarta has to offer in terms of food and drink? Let us use selenium to find it! Understand Selenium and how it extracts food data before continuing with this blog.
Selenium is a Python module that allows you to automate various browsers to perform multiple activities. One example is web scraping, which will enable you to gather important data and information that would otherwise be unavailable.
Selenium refers to several accessible browser automation systems. It provides bindings for all major programming languages, especially Python.
Selenium was initially developed for end-to-end and cross-browser testing (acceptance testing). Today it is mainly used as a standard browser testing tool (e.g., for snapshots), including web scraping and crawling.
Let us systematize the process of scraping through thousands of restaurant web pages using a Python script and the Selenium module. Continue reading the blog to get more details on Food Web Data Extraction using Selenium.
What information will we collect?
Since there is a substantial amount of information available on Zomato, we need to assemble a list of the information we need for our research. We have opted to extract the following after evaluating the Zomato page:
- Name of Restaurant
- Category
- Location
- Comments
- Rating
- Price for 2
- Advanced Facilities or Info
- Longitude & Latitude
Primary Procedure
The first step is to make sure we have the required library called Selenium since we will be using it. Although Selenium is a library for managing web browser processes, we need to download a real browser to the computer and the browser device, to manage it.
You can install a web driver from Google, which we will use.

Analyze the search results
Checklist of websites of restaurants in Jakarta
Selenium is suitable for finding HTML components using various methods such as id, class name, XPath, tag name, CSS selector, or link text. In this blog, we will discuss some issues encountered while Scraping Food Data from the Zomato page and then explain how to fix them.
Let us take a look at the search results page given below. If we specify a location in Jakarta, there are about 1002 pages with 15 restaurants per page. So there are about 15,000 places to eat in Jakarta. Wow, that's incredible!
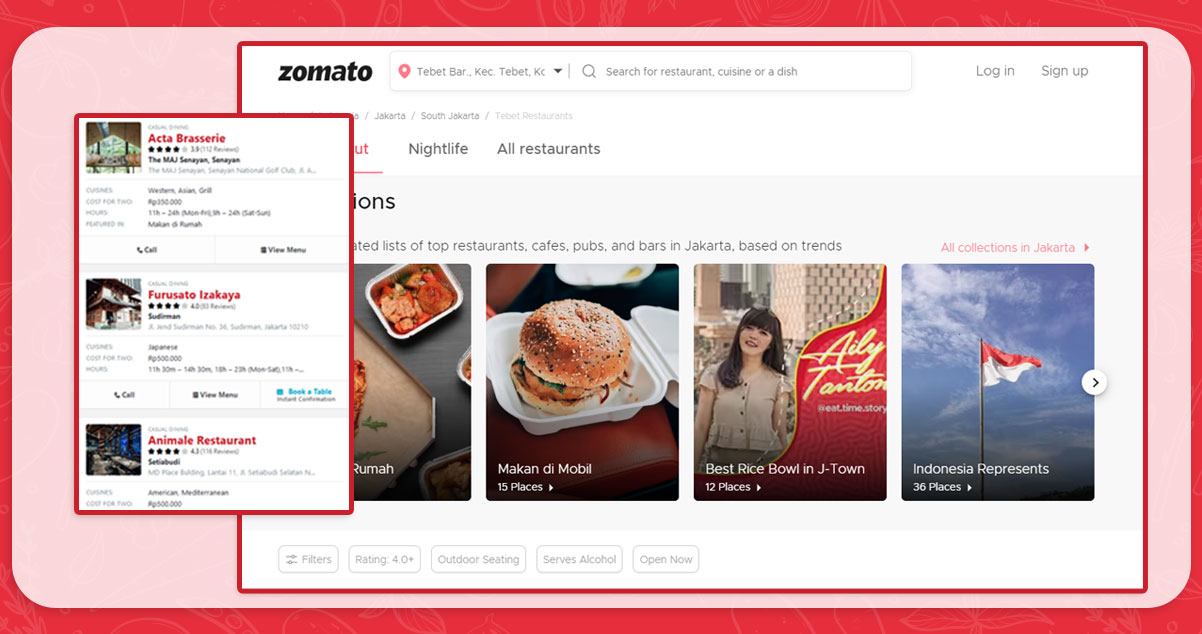
Today, all we need to retrieve from any search results page is the URL of a website. Therefore, any of us can open it. Imagine opening more than 1000 pages automatically; that would be incredibly tiring. Rely on Selenium to save you!
Before we write Python code, we need to understand the differences between the two Selenium "Find Elements" tools.
Retrieve Element:
Retrieve a single component by specifying the location of any HTML element.
Retrieve Elements:
Retrieve a list of components by determining the location of a generic HTML element among the design features you want to find.
We would use the get elements function to collect all domain URLs from each search page. We need to examine the HTML code of a page and then find a standard HTML code for all URLs on each search results page.
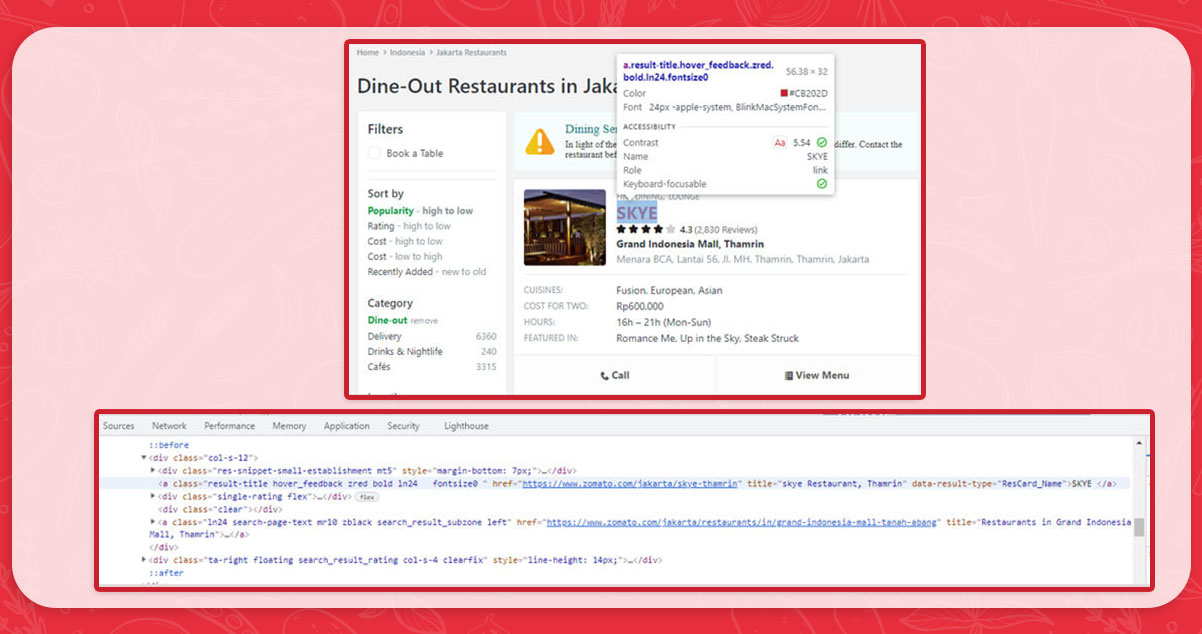
According to our analysis of the search page's web URLs, the code is one of the standard HTML components of a web address.
If you write the code the following way, you will get a list of Selenium Web Elements:
url_elt = driver.find_elements_by_class_name("result-title")It seems simple enough, but our goal is a domain address. We need to develop additional code to extract the features of a URL page from all the web elements by going through a list.
With the code provided, we can generate a list of domain names. So let us combine that with the rules for looping over the Zomato results page that contains all 1002 pages.

The actual code for collecting website addresses has already been provided, but we can make it even better by creating code that shows how data scraping has evolved.


With two simple print scripts, we can get relevant messages every time we iterate over the results page.
Remember to convert a complete list to a Panda's DataFrame so you can organize the information correctly.
out_df = pd.DataFrame(out_lst, columns=['Website'])Result:
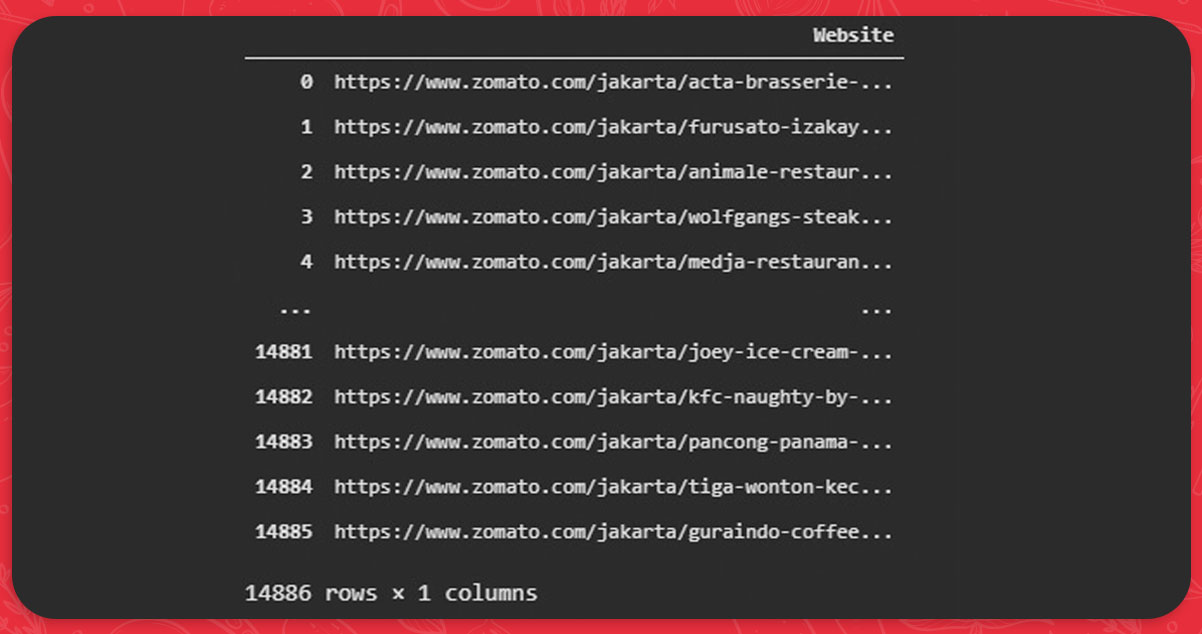
Listing the web addresses of all restaurants that deliver in Jakarta
Then we will use a similar procedure to obtain a list of restaurants in Jakarta that offer delivery. The URL of a search results page and the total number of results pages we have to navigate through are the main differences.

Result:

Eliminating Similar Website URL
There are now 14886 restaurants in Jakarta, of which 3306 offer delivery options. Before we delve deeper into online scraping, we need to ensure that we do not get duplicate listings because the page displaying results may contain recurring listings.
We can quickly determine this by repeating a simple panda technique.

In the above code, we would see a list of site addresses replicated in a data structure in addition to the original entry of duplicated addresses.
We need to construct a new data frame without repeated values for the data frame for different restaurants and the data structure for restaurants with delivery service.

Examine each restaurant's page separately
About 14500 eateries in Jakarta have unique web addresses that we have. With its help, we can access all web addresses and retrieve the necessary data. Let us develop more programs now!
Name of the Restaurant
name_anchor = driver.find_element_by_tag_name('h1')Remember that a search component returns the Selenium web module, so we need to extract it further to find the data we need. In this scenario, we could use the code provided.
name = name_anchor.textLet us look at the entire code for extracting the name of a restaurant:

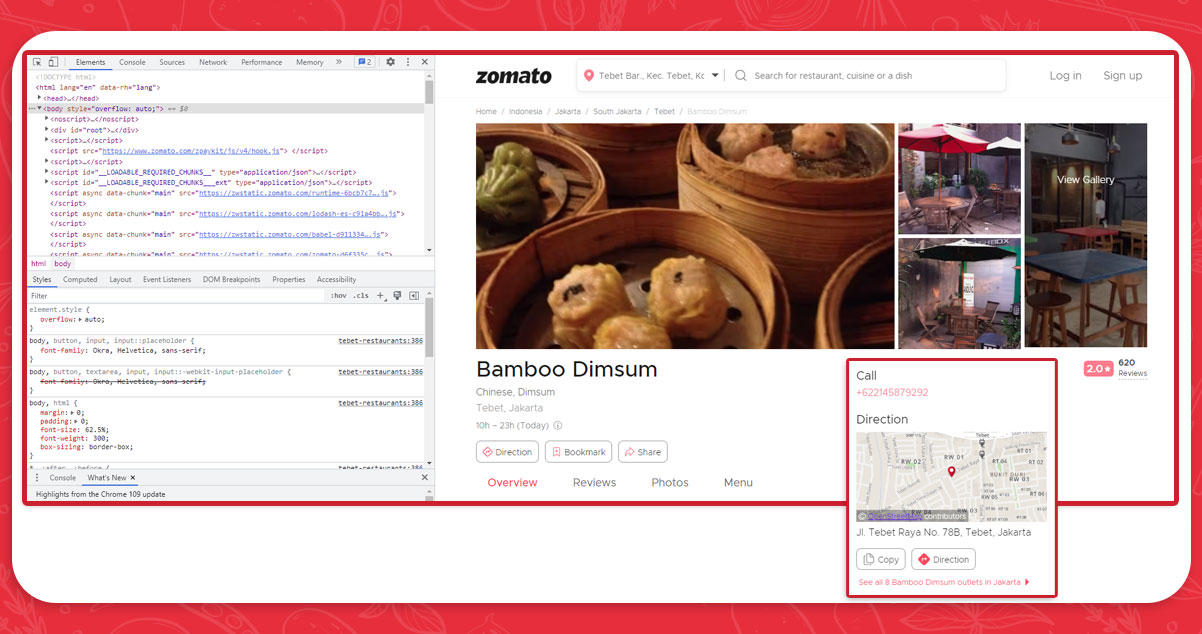
After a few hours or minutes of retrieving restaurant pages, your software may stop and display an error report because the h1 data of some websites cannot be read. There are numerous sites like this on Zomato:
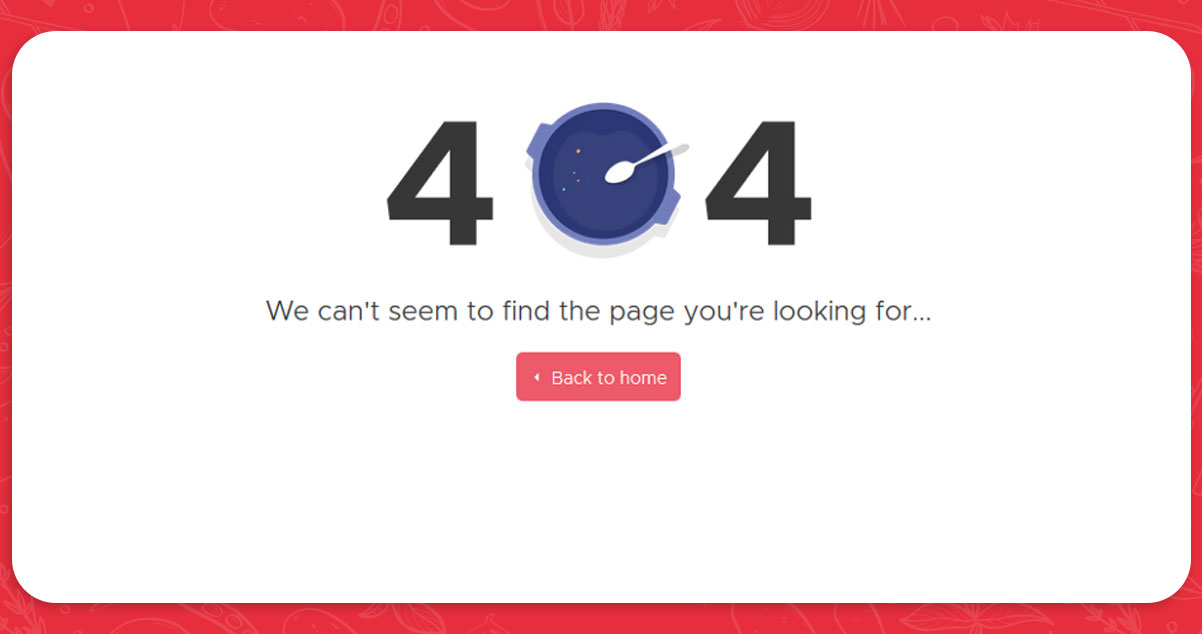
When the browser lands on the page, the application stops because it cannot retrieve the h1 data. We could probably solve this problem using other methods in the Selenium library, such as the NoSuchElementException. If we do not get the desired site components, we can redirect this program to pass them. First, we must import the method at the beginning of a program.
from selenium.common.exceptions import NoSuchElementExceptionAfter that, we would use a try-except statement to add logic to this program. If we cannot find any h1 components, we should insert "404 Error" instead of the restaurant's name and go to the next page.
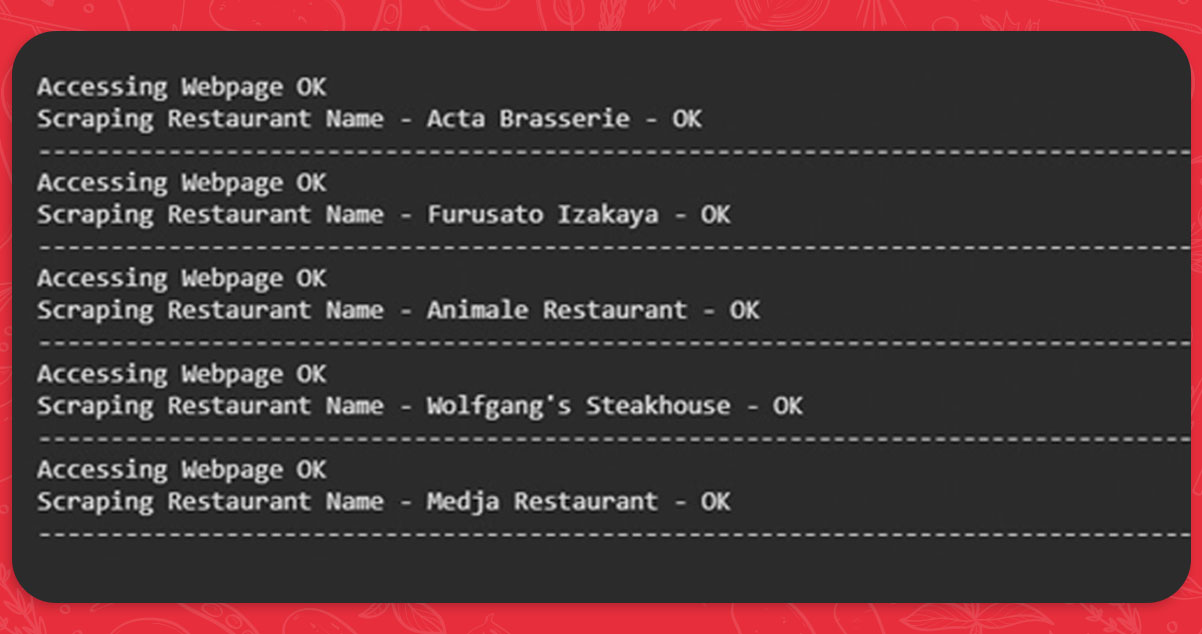
In addition to what we have already done, let us create a few print scripts to demonstrate the development of Selenium food data scraping.

Examine each restaurant's page separately
About 14500 eateries in Jakarta have unique web addresses that we have. With its help, we can access all web addresses and retrieve the necessary data. Let us develop more programs now!
Result:
Type of Restaurant
In the next step, we will filter out all types of restaurants in Jakarta.
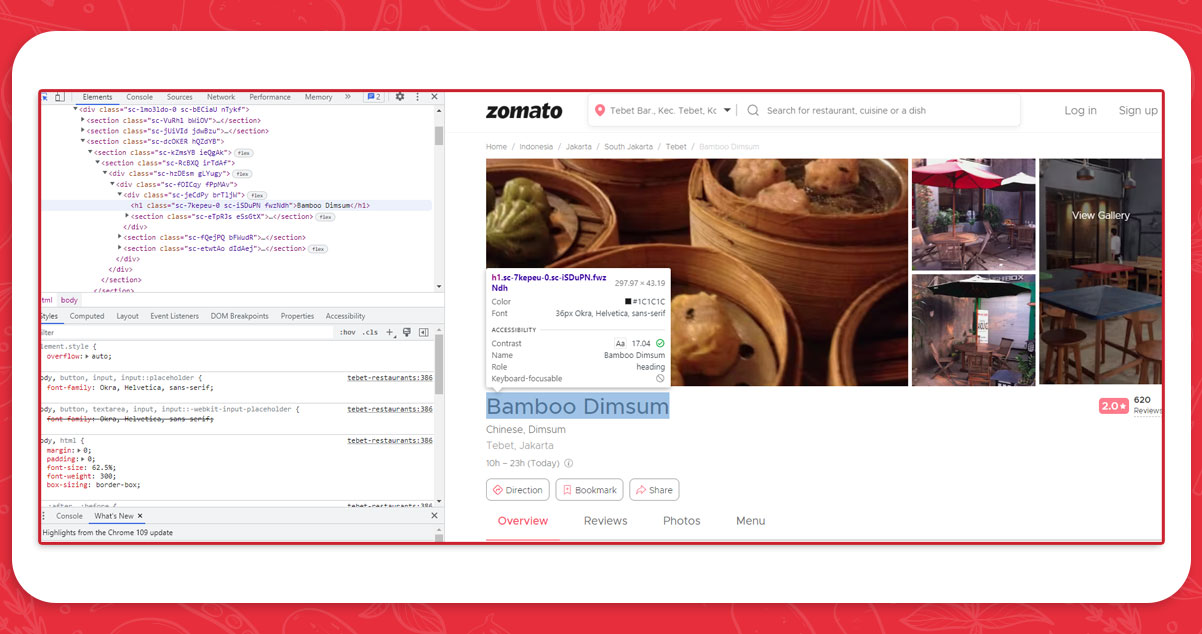
We will look for the elements that resemble a website link because there are several elements that we want to collect. Now, which location should we use to get this element? If we look closely, a tag name is common enough, but a class name (sc-jxGEy0) can change on some restaurant websites, so we cannot retrieve the two locators.
This is where XPath comes into action. XPath stands for XML Path Language and can be used to find an element we want to extract since Zomato's food service page layout is essentially identical.
How does this help you? Select option Copy - > XPath from the context menu when you right-click the appropriate HTML code.
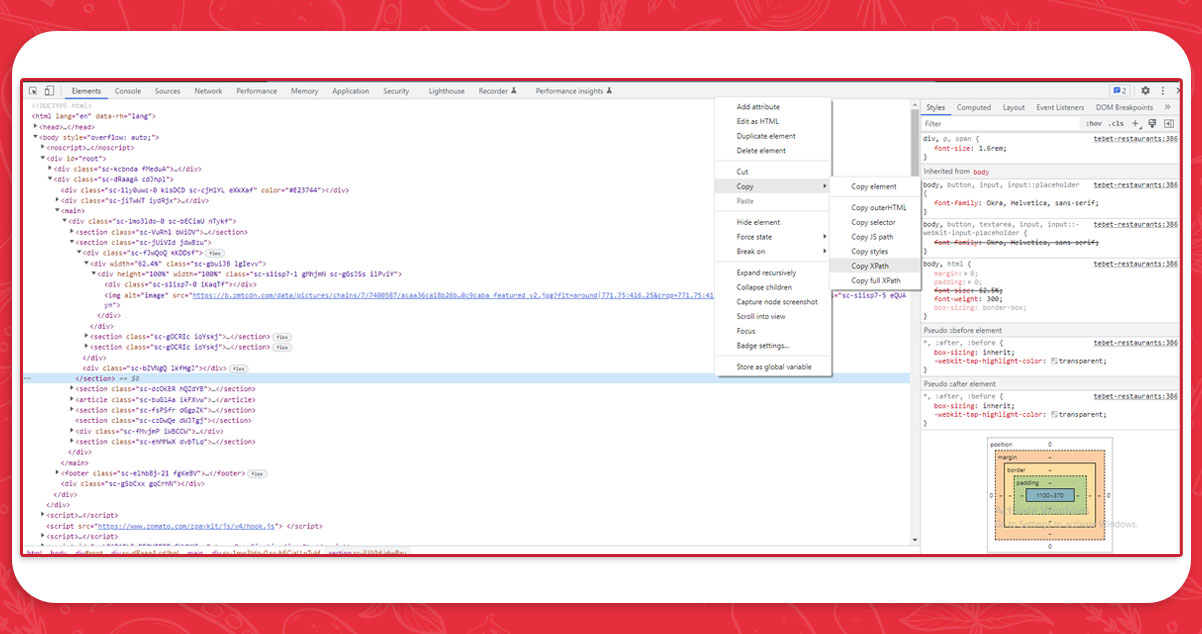
We now need to put this into the programming application and add the code, just as we did with XPath. Note that we must create an initial list with the rest type at the top, similar to the rest name.

Location and Address of The Restaurant
Next, we need to extract the address and area of the restaurant. This is easier because we only need to retrieve 1 feature, and we first capture this data using XPath.

Feedback and Ratings for Restaurants
After extracting name, location, and area, we move on to the slightly more complex data to obtain: Reviews and ratings. As we go along, you'll notice that not all restaurants include this information. We'll call it NoSuchElementException.

Average Restaurant Prices for 2
Until recently, an XPath approach was quite beneficial in extracting important data. For the information, we need to change the "find items by XPath" line and add some if-else expressions. The position on each restaurant page varies for this specific data.
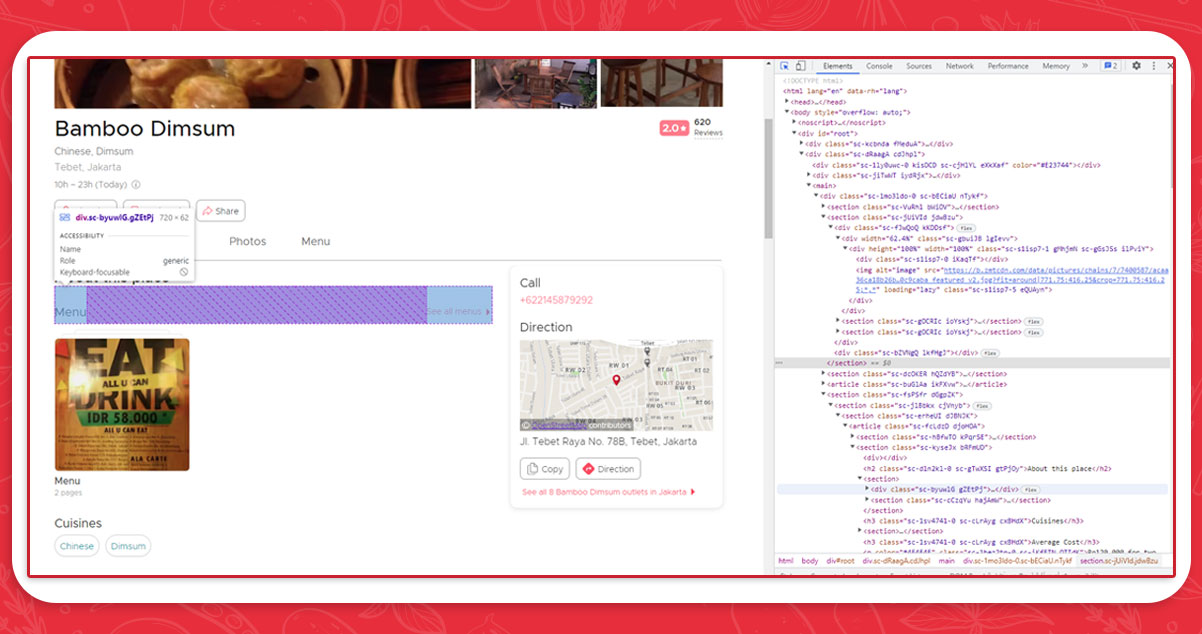
In the figure, an "average price" is listed under "top dishes". You will not find these two data on most Zomato pages. For this reason, the position of the average price is different on the pages that contain these two data.
Using the String Slice tool, we can determine whether the information we extract begins with "Rp" or "No" Another XPath would be removed if it did not begin with two strings.
We need to incorporate this consideration into our code immediately.


Additional Information About the Restaurant
We have retrieved web elements with multiple locators, different web elements with comparable class names, and different online elements in XPath. Now we are going to learn how to extract something new!

In this image, you can see that we want to remove all the text data enclosed in a blue box. If we look at the HTML codes on the left, the data is split into multiple codes.
To extract effectively, we would use XPath to capture the elements of the blue box and then use the results to get the individual text elements with the tag name p.
#Restaurant Additional Information
Geographical Location of Restaurants
Data scraping is more complicated today than ever before. To see why to, consider the following:
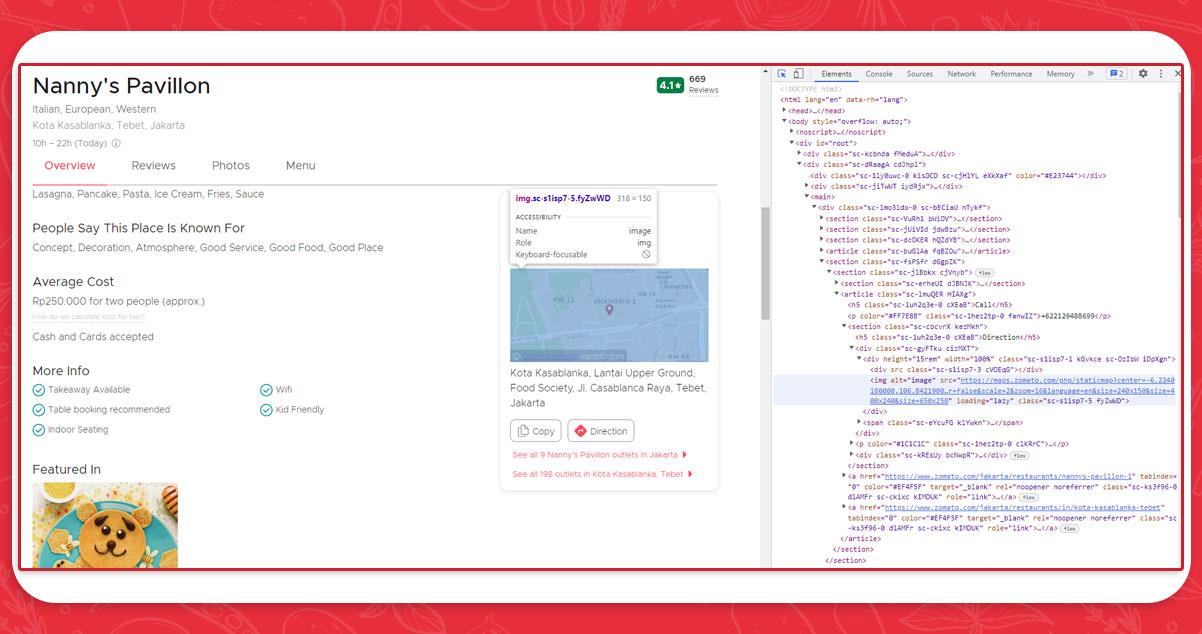
the directions to each restaurant are contained in the URLs of the map. We do not need to access a map's web URLs to extract location coordinates.
We can simply read the URL domains of web components and use Python's string methods!
#Restaurant Latitude and Longitude
Things to consider
Now that we have written a separate program for each piece of information we want to extract, we can link them all together to retrieve that information from each page.
But first, we import another essential library that we can use to interrupt the execution of the application.
Depending on the speed of our Internet connection and the type or amount of data we want to retrieve, we may have to wait for the browser to load a website.

Data extraction from each restaurant
If we combine all the supplied codes, we get them, if we apply them, we can use them to trace the progress of a data scraping unambiguously (and you could also check if there were any errors in that scraping process!)
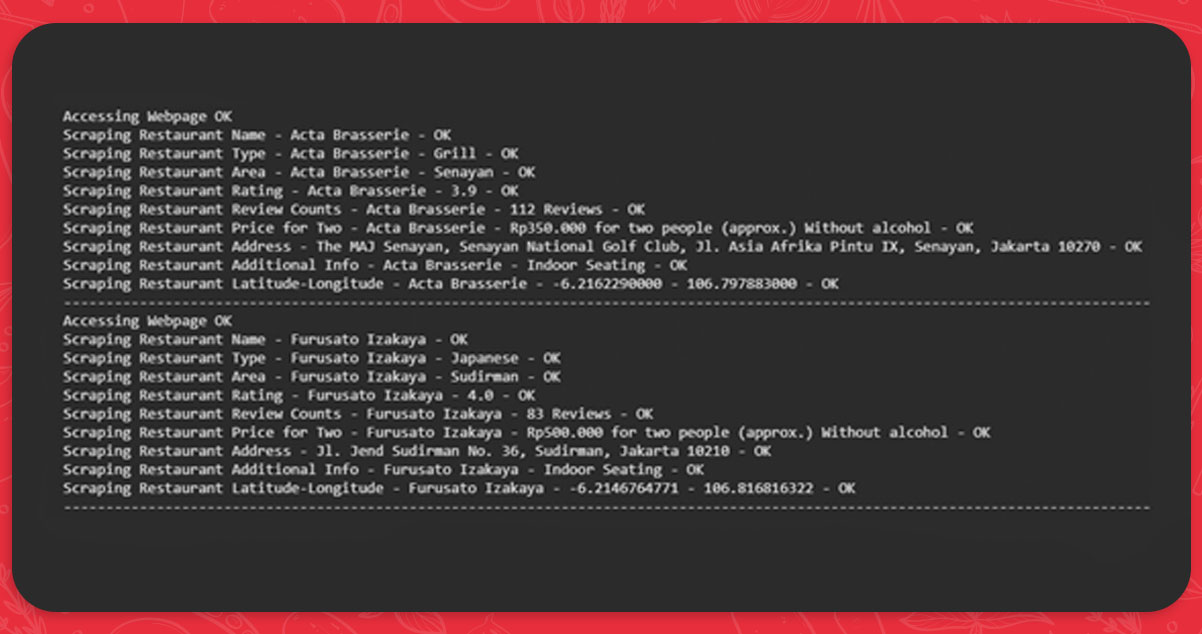
Remember that the scraped results are a list collection. We need to join them to create a small and clean dataset.

Result:
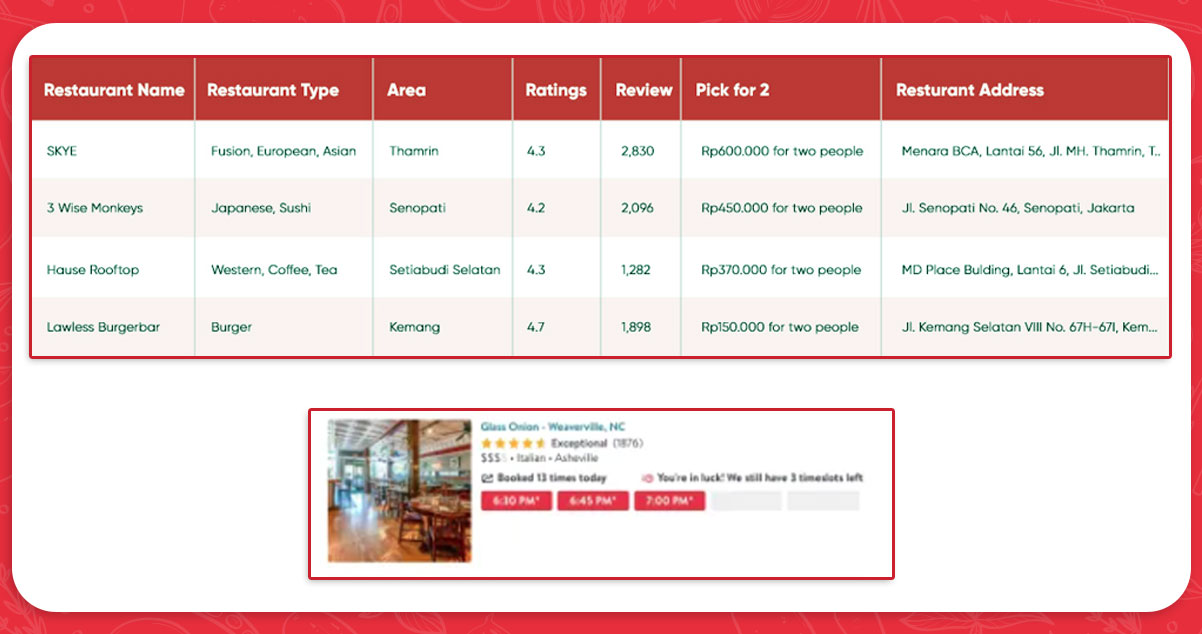
Get the complete code to extract specific restaurant web pages here.
Conclusion
However, the end product is this table! We now have all the information about local restaurants in Jakarta that Zomato was supposed to provide. You have figured out how to get restaurant data from Zomato. In the process, you have learned some strategies for dealing with various HTML codes. In this blog, we have covered everything about Food Web Data Collection with Selenium.
If you want to hire companies that offer Food Data Scrape services, we have all the solutions. Visit our website to learn more about Food Data Scraping and Mobile Grocery App Scraping