Food recipe blogs are known to be the goldmine of delicious recipes. You can easily crawl and extract several recipes for using them in several businesses dealing with food. Several restaurants and companies can leverage the benefits of scraped data to enhance their products and offerings. However, there are multiple variants of automated data extraction. You can use mass-scale crawl for data extraction if there are minimal recipe blogs. But, if there is a large amount of data, using a site-specific crawl is better. Scraping data from food recipe blogs is a technology-tedious task and requires a specialized web crawling service provider.
Who Can Benefit from Food Recipe Data?
Restaurants: By scraping food recipe data, you can have a massive collection of databases enriched with great recipes from the web, indicating that restaurants have more options for satisfying customers' needs. This data will provide a clear idea about what customers like the most and check for the ratings and reviews if mentioned on the blogs. Overall, the food recipe blog data will provide a clear insight into the food industry and help you enhance your customer experience, generating maximum profits.
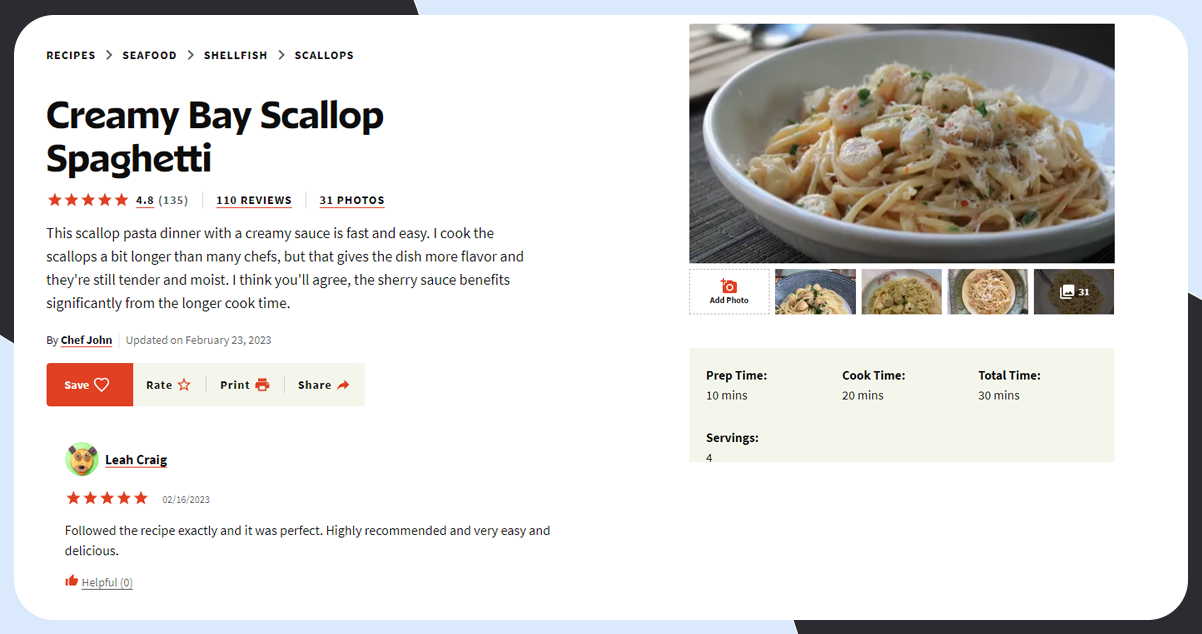
Recipe Apps and Sites: If you are considering creating a website or app exclusive to food recipes, scraping data from food recipe blogs is a great option. The internet contains blogs with helpful information on recipe types, trending recipes, the highest demanding recipes, restaurants offering the best recipes, and more. Extract these data and use them to enhance the development of the website or app.
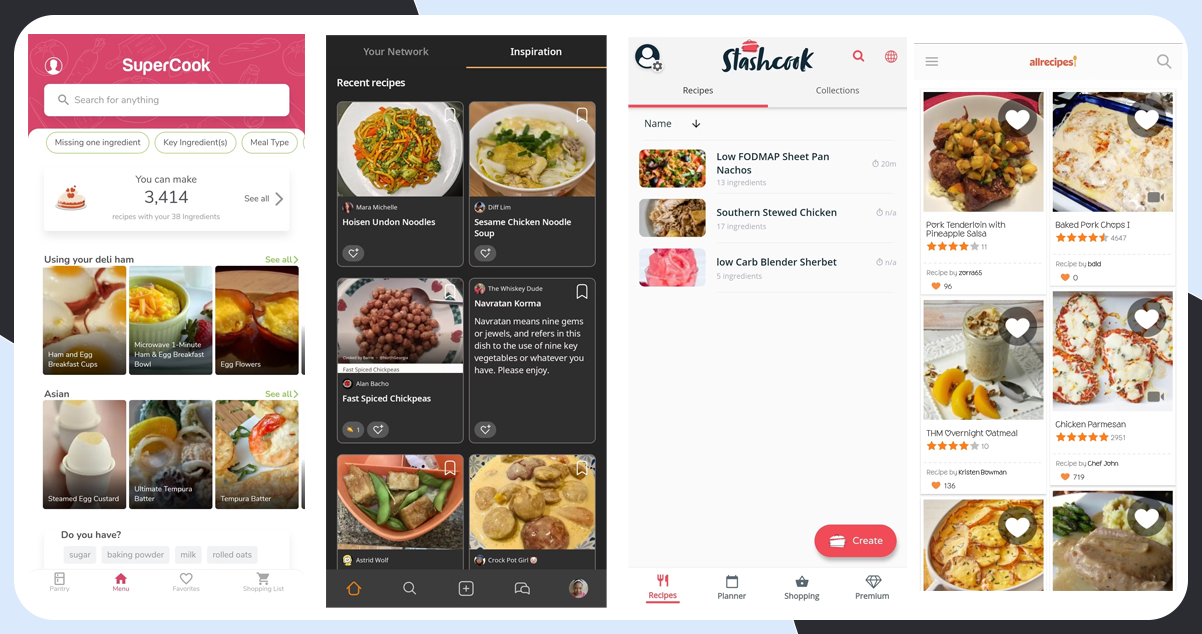
As we have understood the importance of scraping data from food recipe blogs, let’s now understand the procedure of scraping:
In this blog, we will scrape at least 100 recipes from the web, provide their ingredient lists, and then clean the data for further calculation.
Web Scraping Recipes
We will use code to download HTML content and extract the information using requests and BeautifulSoup.
To extract useful information, we use requests and regex.
Requests: A Python module sends HTTP requests for retrieving content.
BeautifulSoup: It parses the HTML or XML documents into a structured format.
Understanding the HTML
To find out all recipes on the website, we use the HTML structure of one page.
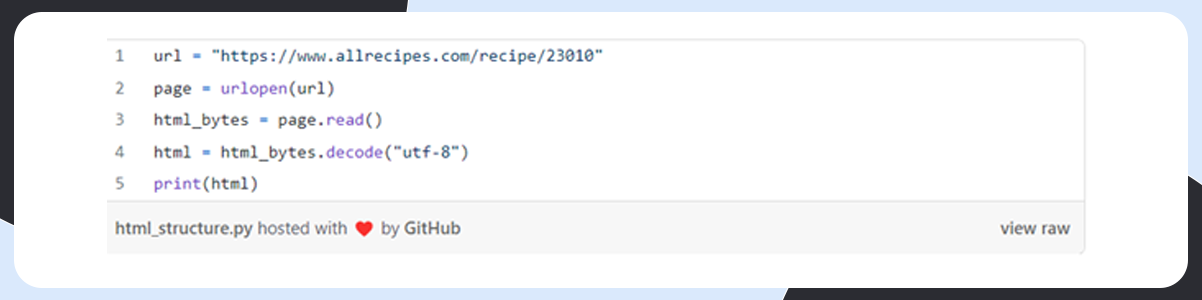
The HTML structure appears like this:

We found several unwanted pieces of information by looking into the above HTML structure. The regex will extract the recipe name and ingredient list.
Scrape the Website
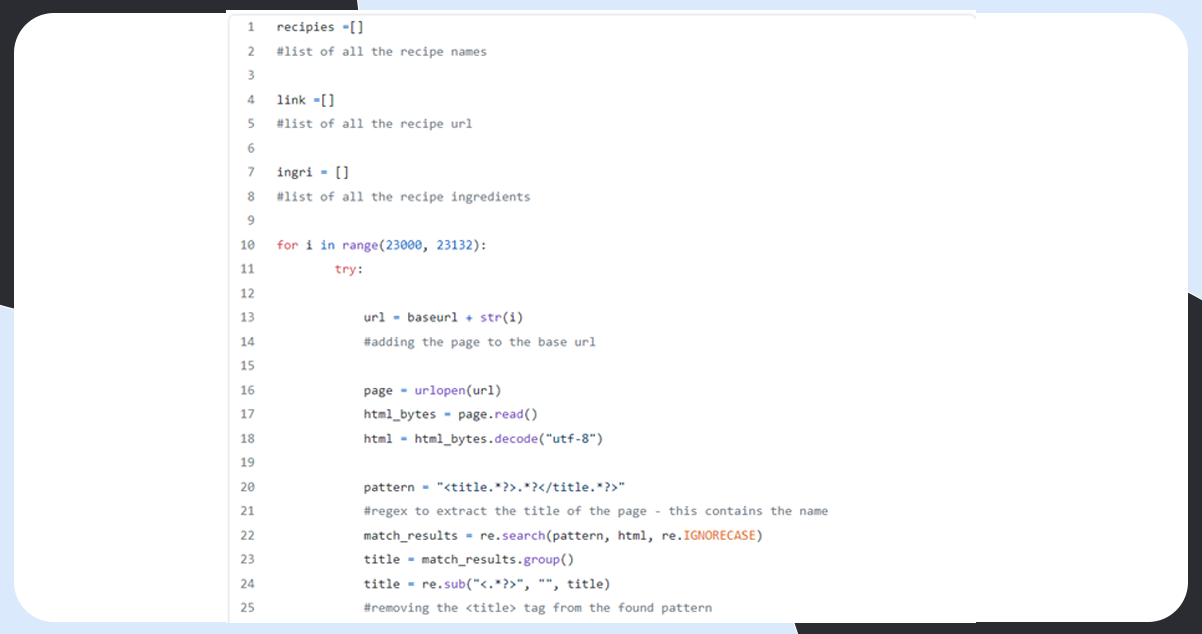
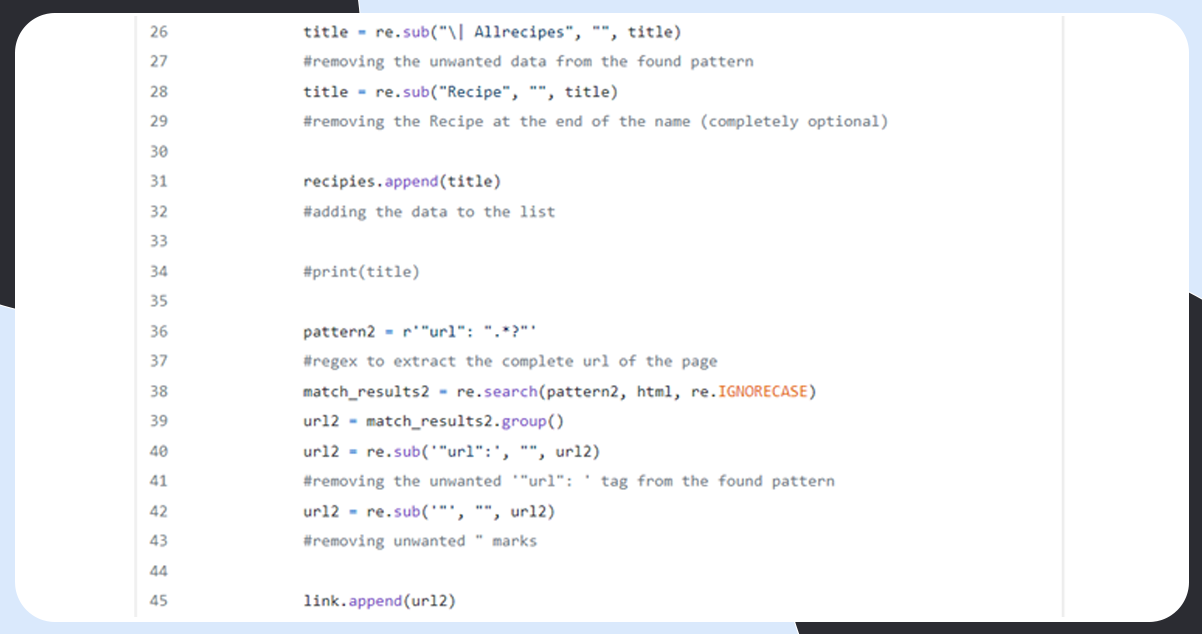
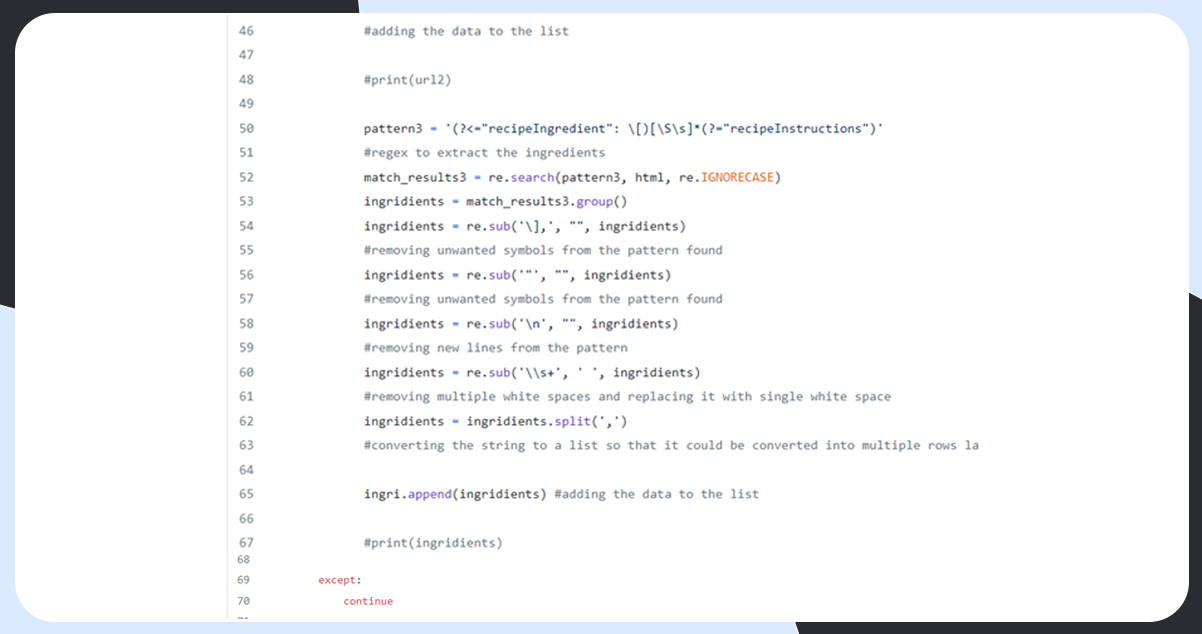
Combine the Data into a Data Frame
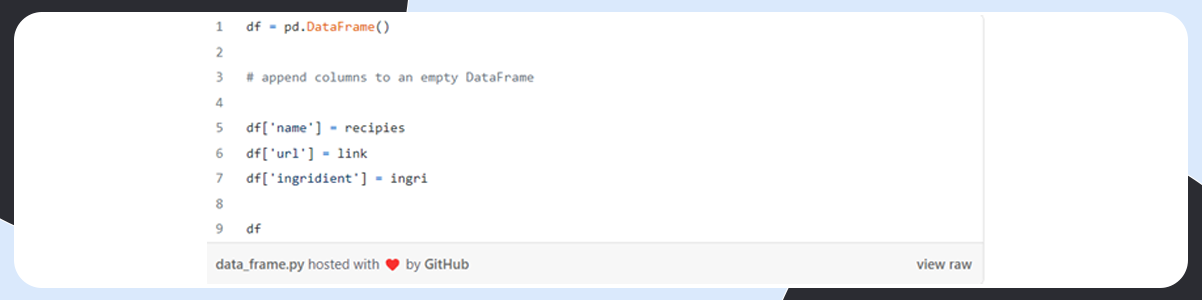

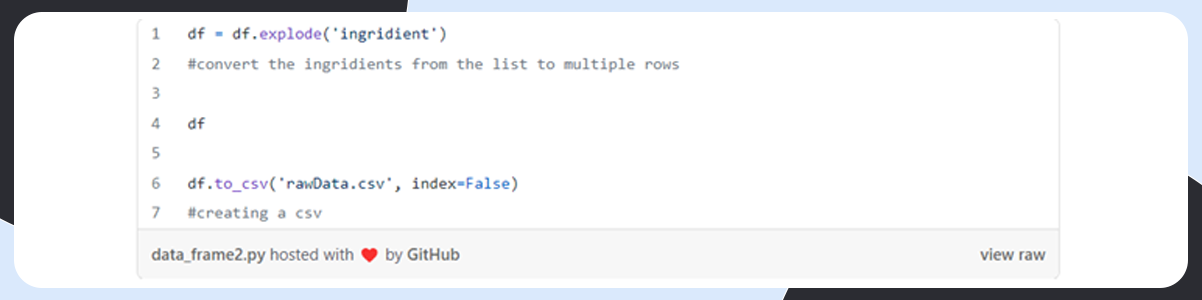
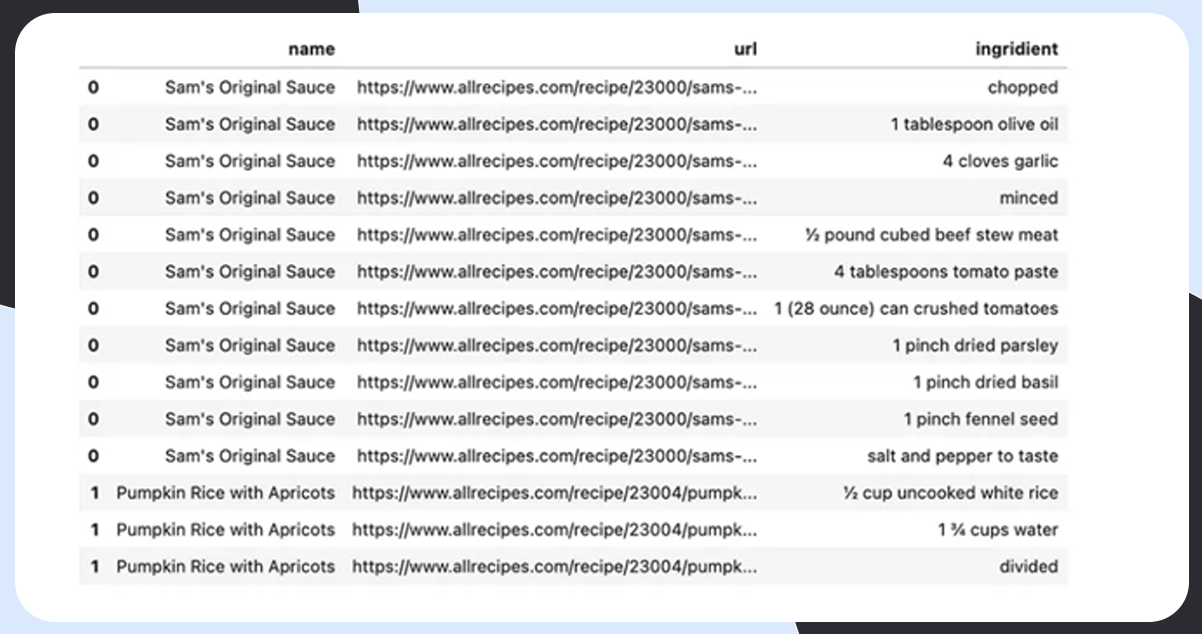
Cleaning of Scraped Data
Here, we will clean the data in primary and problem-specific phases.
Primary Cleaning

Problem-Specific Cleaning
The objective here is to extract the ingredient name from the sentences containing extra information like measurement, units of measurement, and other information like chopped, minced, etc.
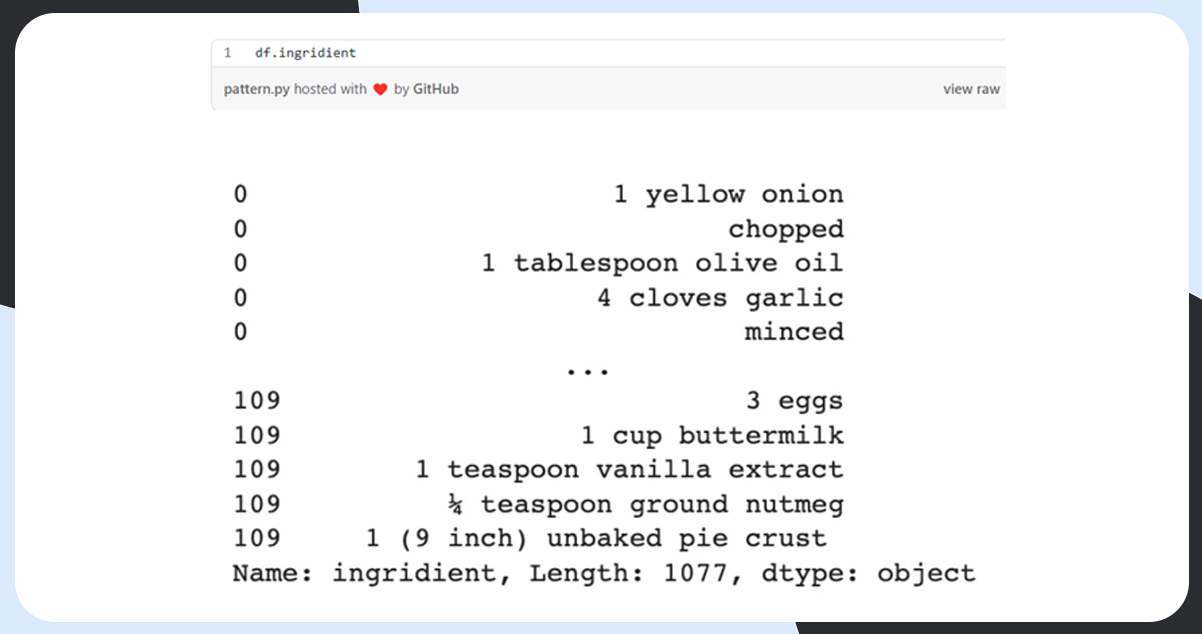
Let’s check if there is any overlap in the cleaned data.
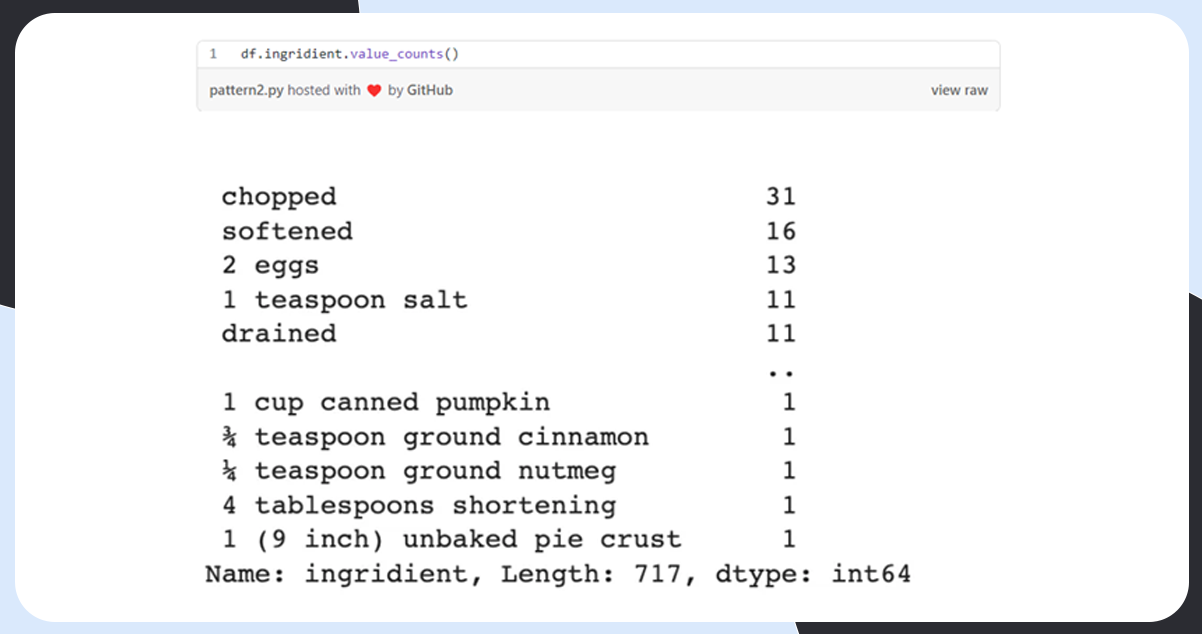
Analysis & Calculation
Count of Calculation
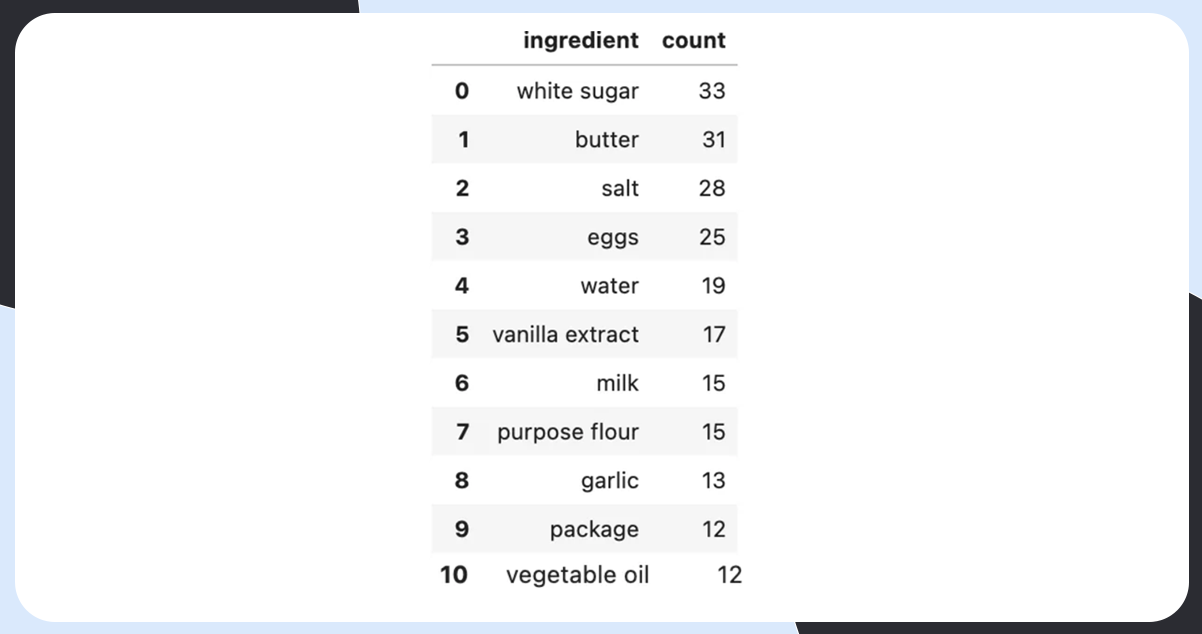
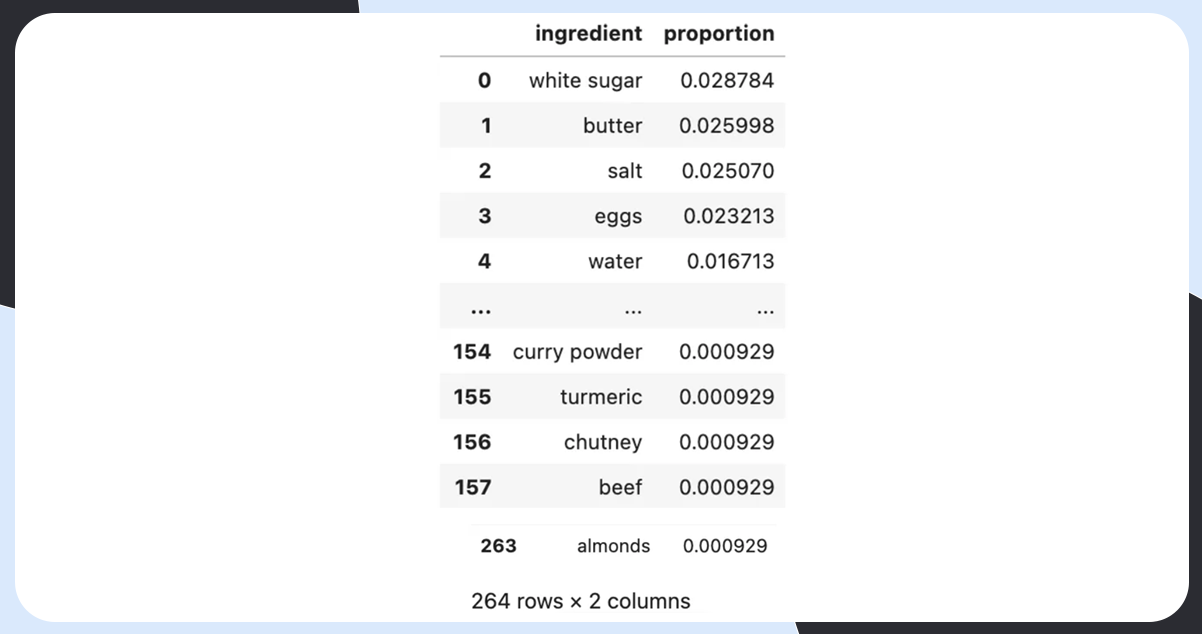
There is a total of 264 unique ingredients.
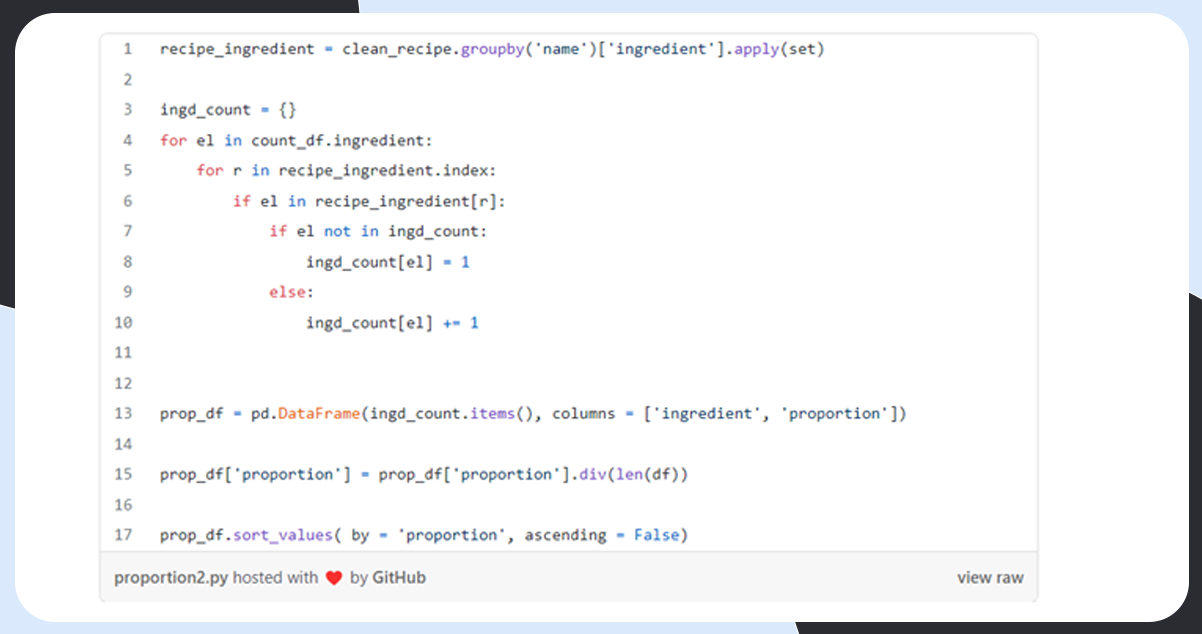
Proportion Calculation
Let’s see if one ingredient appears in more than one recipe. If not, the count divided by the number of recipes will give us the proportion.
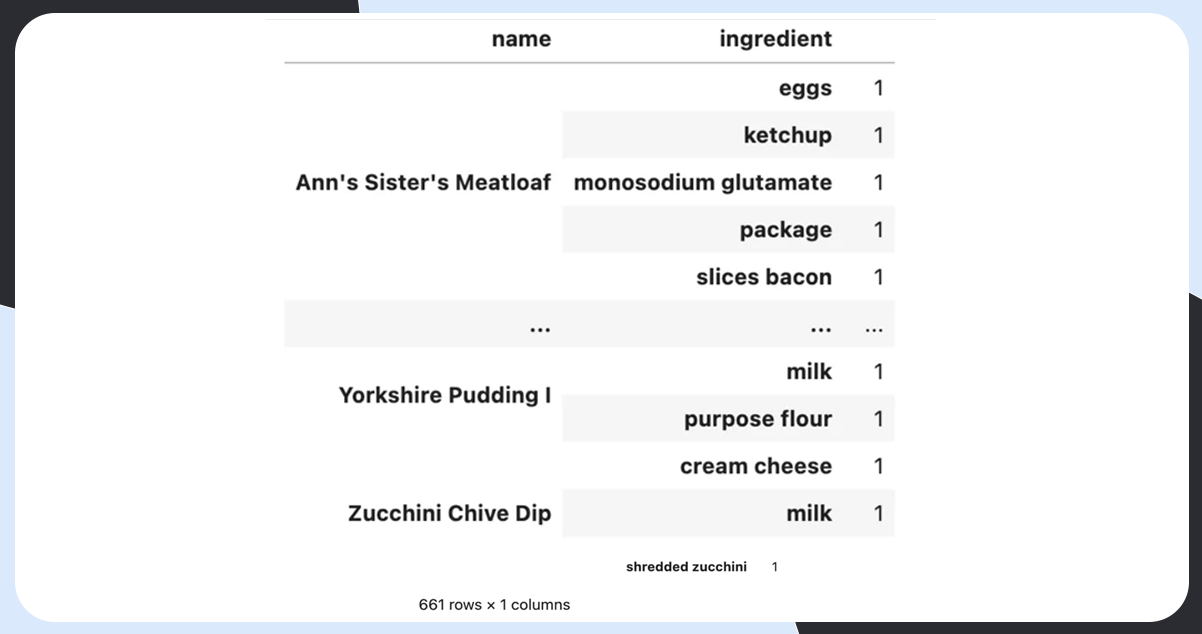
A few recipes contain the same ingredients multiple times, which can be because of the variation in ingredients. So, we first find the ingredients set adhered with each and then count each ingredient’s occurrence.
Conclusion
The above-mentioned is an example of how to scrape data from food recipe blogs. In this manner, you can scrape more data from the recipes blog.
For more information, get in touch with Food Data Scrape now! You can also reach us for all your web food data scraping service and mobile app data scraping service requirements.